RAG (Retrieval Augmented Generation)
│
├── RAG Architecture Evolution
│ ├── Naive RAG — Simple chunk → embed → vector search → generate pipeline
│ ├── Advanced RAG — Multi-stage retrieval with pre/post-retrieval optimization
│ ├── Modular RAG — Swappable modules (search, memory, fusion, routing)
│ └── Agentic RAG — AI agent orchestrates retrieval; can search, evaluate,
│ re-search, and use tools adaptively
│
├── Data Ingestion & Indexing
│ │ — Preparing documents for retrieval
│ │
│ ├── Document Loading — Parsing PDFs, HTML, DOCX, markdown, code files
│ ├── Text Extraction — OCR for images, table parsing, metadata extraction
│ │
│ ├── Chunking Strategies
│ │ ├── Fixed-Size Chunking — Split by token/character count (e.g., 512 tokens);
│ │ │ simple baseline
│ │ ├── Recursive Chunking — Split by paragraphs → sentences → characters;
│ │ │ respects document structure
│ │ ├── Semantic Chunking — Embed sentences, detect semantic breakpoints
│ │ │ where topics shift; meaning-preserving boundaries
│ │ ├── Document-Structure Chunking — Split by headers, sections, tables;
│ │ │ preserves document hierarchy
│ │ ├── Agentic/LLM-Based Chunking — Use LLM to identify propositions,
│ │ │ key points, and optimal split boundaries
│ │ ├── Late Chunking — Embed full document first, then chunk;
│ │ │ each chunk retains whole-document context
│ │ └── Chunk Overlap — Repeat 10-20% of tokens at chunk boundaries
│ │ to preserve cross-boundary context
│ │
│ └── Metadata Enrichment — Add source, date, author, section title
│ as filterable metadata alongside each chunk
│
├── Embeddings
│ │ — Converting text to dense vector representations for similarity search
│ │
│ ├── Embedding Models
│ │ ├── OpenAI text-embedding-3-small/large — Proprietary; strong general-purpose
│ │ ├── Sentence Transformers (SBERT) — Open-source; all-MiniLM-L6-v2 is
│ │ │ fast baseline; many specialized variants
│ │ ├── Cohere Embed v3 — Strong multilingual; supports compression
│ │ ├── BGE / GTE (BAAI) — Open-source; top MTEB benchmarks
│ │ ├── Jina Embeddings — Supports 8K context; multimodal variants
│ │ └── Nomic Embed — Open-weight, reproducible, long-context
│ │
│ ├── Embedding Concepts
│ │ ├── Dense Embeddings — High-dimensional float vectors capturing semantic meaning
│ │ ├── Sparse Embeddings — High-dimensional but mostly zeros; capture
│ │ │ exact keyword matches (BM25, SPLADE)
│ │ ├── Cosine Similarity — Measure angle between vectors (most common metric)
│ │ ├── Dot Product — Faster but sensitive to vector magnitude
│ │ └── Matryoshka Embeddings — Embeddings that can be truncated to
│ │ smaller dimensions without retraining; flexible precision/cost tradeoff
│ │
│ └── Embedding Fine-Tuning — Train embeddings on your domain data
│ for better retrieval relevance (using contrastive loss)
│
├── Vector Databases
│ │ — Storage and efficient similarity search over embedding vectors
│ │
│ ├── Index Types
│ │ ├── Flat (Brute Force) — Exact search; accurate but O(n) per query
│ │ ├── IVF (Inverted File) — Clusters vectors; searches only nearest clusters
│ │ ├── HNSW (Hierarchical Navigable Small World) — Graph-based; best recall
│ │ │ vs speed tradeoff; most popular in production
│ │ ├── DiskANN — Billion-scale search on disk; low memory footprint
│ │ └── Product Quantization (PQ) — Compresses vectors for memory savings
│ │
│ └── Notable Vector Databases
│ ├── Pinecone — Fully managed; easiest setup; great for startups
│ ├── Weaviate — Open-source; best hybrid search; GraphQL API
│ ├── Qdrant — Rust-based; fastest performance; rich filtering
│ ├── Milvus — Open-source; designed for billion+ scale; GPU support
│ ├── ChromaDB — Lightweight; best for prototyping and development
│ ├── pgvector — PostgreSQL extension; great if you already use Postgres
│ └── FAISS (Meta) — Library (not DB); fastest raw search; no persistence
│
├── Retrieval Strategies
│ │ — How to find the most relevant chunks for a given query
│ │
│ ├── Dense Retrieval — Semantic similarity via embedding vectors
│ ├── Sparse Retrieval (BM25) — Keyword matching using term frequency
│ ├── Hybrid Search — Combine dense + sparse scores (typically via
│ │ Reciprocal Rank Fusion); best overall recall
│ ├── Multi-Query Retrieval — LLM generates multiple reformulations
│ │ of the query; union of results improves recall
│ ├── HyDE (Hypothetical Document Embeddings) — LLM generates a fake
│ │ answer first, then uses its embedding to search; bridges the
│ │ query-document embedding gap
│ ├── Parent-Child Retrieval — Retrieve small child chunks, but return
│ │ their larger parent chunk for more context
│ ├── Recursive Retrieval — Start with small semantic chunks, retrieve
│ │ progressively larger context chunks
│ └── Contextual Retrieval — Prepend surrounding context to each chunk
│ before embedding (Anthropic technique)
│
├── Reranking (Post-Retrieval Optimization)
│ │ — Reorder retrieved results for precision using expensive but accurate models
│ │
│ ├── Cross-Encoder Rerankers — Process query+document pairs jointly for
│ │ deep relevance scoring; ~10x better precision than bi-encoders
│ ├── Cohere Rerank — Commercial API; plug-and-play reranking
│ ├── BGE Reranker — Open-source cross-encoder reranker
│ ├── Colbert / ColBERTv2 — Late interaction model; token-level matching
│ │ between query and document for fine-grained relevance
│ └── LLM-as-Reranker — Use LLM itself to score/rank retrieved passages
│
├── Advanced RAG Patterns
│ ├── Self-RAG — Model generates reflection tokens to self-evaluate whether
│ │ retrieval is needed and whether generation is grounded
│ ├── Corrective RAG (CRAG) — Evaluator scores retrieved docs; triggers
│ │ web search fallback if retrieval quality is low
│ ├── GraphRAG — Structures knowledge as entity-relation graphs; enables
│ │ multi-hop reasoning across documents; handles "global" questions
│ │ that span multiple sources
│ ├── Adaptive RAG — Dynamically decides WHEN to retrieve based on
│ │ query complexity; skips retrieval for simple questions
│ ├── RAPTOR — Recursively summarizes document tree from leaves to root;
│ │ retrieves at different abstraction levels
│ └── Fusion RAG — Multiple retrieval strategies executed in parallel;
│ results fused via Reciprocal Rank Fusion
│
└── RAG Evaluation Metrics
├── Faithfulness/Groundedness — Does the answer only use retrieved context?
├── Answer Relevancy — Does the answer actually address the question?
├── Context Relevancy — Are the retrieved documents relevant to the query?
├── Context Recall — Were all necessary documents retrieved?
├── RAGAS Framework — Open-source RAG evaluation combining faithfulness,
│ answer relevancy, context precision, and context recall
└── Context Precision — How many retrieved docs are actually relevant?
RAG
RAG stands for Retrieval Augmented Generation, which is a technique to enhance Large Language Models (LLMs) by connecting them to external knowledge bases or datasets. This approach is crucial when LLMs need to answer questions about specific products, services, or domains they haven’t been trained on. A practical example is building a chatbot for a website that needs to provide information about the site’s specific products and services.
How RAG Works
The basic version of RAG, called Naive RAG, involves several steps:
- Knowledge Base Preparation: Dividing the data into smaller chunks, embedding them (converting into numerical representations), and storing them in a vector database.
- Query Processing: When a user submits a query, it’s embedded and compared to the embedded chunks in the database using semantic matching (a technique to determine the similarity of meaning between pieces of text) to find the most relevant information.
- Contextualized Response: The retrieved context is then sent to the LLM along with the original query, allowing the LLM to generate a response informed by the relevant knowledge.
There are many RAG pipelines and modules out there, but you don’t know what pipeline is great for “your own data” and “your own use-case.” Making and evaluating all RAG modules is very time-consuming and hard to do. But without it, you will never know which RAG pipeline is the best for your own use-case.
https://github.com/Marker-Inc-Korea/AutoRAG/
MSRS: Evaluating Multi-Source Retrieval-Augmented Generation
We used to think that a good answer for an AI system would be found neatly in just one document or piece of information. But in the real world, like when you’re doing a big research project or trying to understand a complex meeting, the answer isn’t in one place; it’s scattered across many different sources – like different chapters in a book or various transcripts from different meetings. Current AI systems, when faced with this “messy” real-world information, often fail
So to test that they have created the benchmark
Graph Rag with light rag
https://github.com/apecloud/ApeRAG
Chunking Methods
-
Naive chunking: A simple method that divides text based on a fixed number of characters, often using the
CharacterTextSplitterin Langchain. It is fast and efficient but may not be the most intelligent approach as it does not account for document structure. -
Sentence splitting: This method uses natural language processing (NLP) frameworks like NLTK or SpaCy to split text into sentence-sized chunks. It is more accurate than naive chunking and can handle edge cases.
-
Recursive character text splitting: This method, implemented using the
RecursiveCharacterTextSplitterin Langchain, combines character-based splitting with consideration for document structure. It recursively splits chunks based on paragraphs, sentences, and characters, maximizing the information contained within each chunk while adhering to the specified chunk size. -
Structural chunkers: Langchain provides structural chunkers for HTML and Markdown documents that split text based on the document’s schema, such as headers and subsections. This method is particularly useful for structured documents and allows for the addition of metadata to each chunk, indicating its source and location within the document.
-
Semantic Chunking: This strategy uses embedding models to analyze the meaning of sentences and group together sentences that are semantically similar. It results in chunks that are more likely to represent coherent concepts, but it requires more computational resources than other methods. check out the nice article to visulize the chunking here
Page index
PageIndex can transform lengthy PDF documents into a semantic tree structure, similar to a “table of contents” but optimized for use with Large Language Models (LLMs). It’s ideal for: financial reports, regulatory filings, academic textbooks, legal or technical manuals, and any document that exceeds LLM context limits.
Late Chunking
- Let say we have doc as
Berin is captial of germany it is more then 3M populationif we chunk asBerin is captial of germanyandit is more then 3M populationin second chunk we loose the context to avoid that - We first applies the transformer layer of the embedding model to the entire text or as much of it as possible. This generates a sequence of vector representations for each token that encompasses textual information from the entire text. Subsequently, mean pooling is applied to each chunk of this sequence of token vectors, yielding embeddings for each chunk that consider the entire text’s context
- It required large context window model
The process of converting a sequence of embeddings into a sentence embedding is called pooling
Mean pooling in Natural Language Processing (NLP) is a technique used to create a fixed-size vector representation from a variable-length input sequence, such as a sentence or document. It works by averaging the vectors of all tokens (words or subwords) in the sequence
- Tokenization: The input text is split into tokens (words, subwords, or characters).
- Embedding: Each token is mapped to a corresponding vector using an embedding layer (e.g., pre-trained embeddings like Word2Vec, GloVe, or BERT embeddings).
- Mean Pooling: The vectors of all the tokens in the sequence are averaged to produce a single vector. This can be done by summing the vectors and then dividing by the total number of tokens.
How it worsk under the hood
- Send the whole document ang get embedding for it
model_output[0] = [
# Each inner list represents the embedding of a token
[0.1, 0.2, 0.3], # Token 1 embedding
[0.4, 0.5, 0.6], # Token 2 embedding
[0.7, 0.8, 0.9], # Token 3 embedding
[1.0, 1.1, 1.2] # Token 4 embedding
]- Next chunk the the document based on chunk size and get the starting index and ending index for each document
span_annotation = [
[(0, 2), (2, 4)] # Pool embeddings over tokens 1-2 and tokens 3-4
]- Calculate the pool embedding for each chunks as
- For
(0, 2): Pool over tokens 1 and 2:
- For
pooled1 = [0.1,0.2,0.3]+[0.4,0.5,0.6] / 2 = [0.25,0.35,0.45]
pooled2 = [0.7,0.8,0.9]+[1.0,1.1,1.2] / 2 = [0.85,0.95,1.05]
The final outputs would contain these pooled embeddings as numpy arrays:
outputs = [
[[0.25, 0.35, 0.45], [0.85, 0.95, 1.05]]
]- Now store this in DB which have more context
Agentic Chunking
- Analyzes document structure using LLMs to identify logical boundaries
- Preserves semantic relationships across different content types
- Adapts chunk sizes based on content complexity and context
- Enriches chunks with metadata for improved retrieval accuracy
Prompt
You are an AI assistant helping to split text into meaningful chunks based on topics.
Evaluating Chunking Strategies for Retrieval
-
https://research.trychroma.com/evaluating-chunking The Chroma DB evaluation framework
-
They have framework where we can run and evalute the different chunking stregtegy
Resources
RAG Optimization Techniques
Optimizing a RAG system can be complex, involving several techniques that can be broadly categorized into four buckets:
- Pre-Retrieval Optimization: Focusing on improving the quality and retrievability of data before the retrieval process.
- Retrieval Optimization: Enhancing the actual retrieval process to find the most relevant context.
- Post-Retrieval Optimization: Further refining the retrieved information to ensure its relevance and conciseness.
- Generation Optimization: Optimizing how the LLM uses the retrieved context to generate the best possible answer.
Specific Examples of RAG Optimization Techniques
The sources highlight a few specific examples of RAG optimization techniques.
1. Pre-Retrieval Optimization
-
Improving Information Density: Unstructured data often has low information density, meaning the relevant facts are scattered within large volumes of text. This can lead to many chunks being sent to the LLM, increasing costs and the likelihood of errors. One solution is to use an LLM to pre-process and summarize the data into a more factual and concise format. A case study using GPT-4 to summarize financial services web pages showed a 4x reduction in token count, leading to improved accuracy.
- GRAPH based RAG
-
Query Transformation: User queries are often poorly worded or overly complex. Query transformation involves rewriting or breaking down queries to improve their clarity and effectiveness for retrieval. LLMs can be used for this task. For example, an LLM can rewrite a query with typos or grammatical errors or break down a complex query into multiple sub-queries. Another example involves handling conversational context by identifying the core query from a series of user interactions, ensuring the retrieval focuses on the current topic and avoids retrieving irrelevant past information.
- Note : when doing query rewriting make sure that you llm understand the your domain specfic question and convert that to domain specfic question instead of un usefull question
2. Retrieval Optimization
-
Ensemble/Fusion Retriever: This technique combines traditional keyword search (lexical search) with semantic search (vector search) to improve retrieval effectiveness, especially for domain-specific data where embedding models might not perform well. Two retrievers, one for each search type, run in parallel, and their results are combined using a technique like reciprocal rank fusion to produce a consolidated ranking of relevant chunks. Experiments by Microsoft have shown significant improvement in retrieving high-quality chunks using hybrid retrieval methods.
-
Hypothetical Document Embeddings (HyDE) : This works well for the code. so when user asked question instead of directly use that to search get answer from LLM and use question and answer to search on which give better result check here for more
-
Meta-characteristic search (FOR CODE): when we embedding the code attach the meta data like what it do and other thing get from LLM and embed that such that it will help when user do query realted to functionallity
3. Post-Retrieval Optimization
- Cross-Encoder Reranking: This technique addresses the limitations of bi-encoder-based semantic search, where a single vector representation for a document might lose crucial context. Reranking involves using a cross-encoder, which processes both the query and the retrieved chunks together to determine their similarity more accurately, effectively reordering the retrieved chunks to prioritize the most relevant ones. This is particularly useful for pushing highly relevant chunks initially ranked lower due to the limitations of bi-encoders to the top of the results list. Due to its computational cost, cross-encoder reranking is typically used as a second stage after an initial retrieval method.
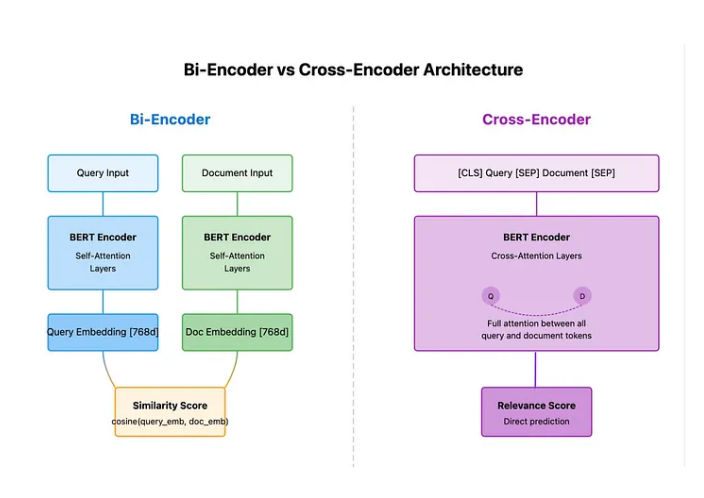
The key to cross-encoders’ effectiveness is how they process query and document tokens together in a single sequence.
-
Query and document are concatenated:
[CLS] query [SEP] document [SEP] -
Special tokens ([CLS], [SEP]) help model understand sequence structure
-
Query and document tokens can directly attend to each other
-
Each token can attend to every other token
-
Strong attention between matching terms (e.g., “neural” → “neural”)
-
Contextual attention between related terms (e.g., “networks” → “patterns”)
-
[CLS] token aggregates cross-sequence interactions
Retrevial types
Rank GPT
- instead of just querying in vector and sending to LLM after querying ask LLM can you rank the doc that fetched from vecotr db based relvant to the query and again send to LLM with re ranked doc
Multi query retrieval
- Send the user query to LLM and ask can you suggest revelant query to this query get that and use that query to get from db
Contextual compression
- Ask the LLM can you give relavant part that required for the doc by asking this we reducing the context then again send to LLM
Hypothetical document embedding
- ask LLM to suggest Hypothetical document for query and use that to fetch from DB
Retrevial Algorithm
- Cosine Similarity and Euclidean Distance
- Graph-Based RAG
- Exact Nearest Neighbor (k-NN) Search
- Hierarchical Navigable Small Worlds (HNSW): A popular ANN algorithm that constructs a graph-like structure for fast similarity searches. It’s highly scalable and suited to high-dimensional data.
- Product Quantization (PQ): Used to reduce storage requirements and speed up searches by dividing vectors into smaller, quantized components.
- Locality-Sensitive Hashing (LSH): This algorithm hashes input vectors so that similar vectors map to the same hash, allowing fast lookup based on hash values rather than full comparison
- BM25 (Best Matching 25) Unlike vector-based search, which relies on embeddings, BM25 is a term-based algorithm that ranks documents based on the presence and frequency of query terms in the documents.
RAG Fusion
How it works
-
Multi-Query Generation: RAG-Fusion generates multiple versions of the user’s original query.This is different to single query generation, which traditional RAG does. This allows the system to explore different interpretations and perspectives, which significantly broadens the search’s scope and improvs the relevance of the retrieved information.
- Use AI to generate the multiple version of the user query
-
Reciprocal Rank Fusion (RRF): In this technique, we combine and re-rank search results based on relevance. By merging scores from various retrieval strategies, RAG-Fusion ensures that documents consistently appearing in top positions are prioritized, which makes the response more accurate.
-
Improved Contextual Relevance: Because we consider multiple interpretations of the user’s query and re-ranking results, RAG-Fusion generates responses that are more closely aligned with user intent, which makes the answers more accurate and contextually relevant.
Resources
- Not RAG, but RAG Fusion?
- https://github.com/Raudaschl/rag-fusion
- https://github.dev/Denis2054/RAG-Driven-Generative-AI
CRAG
Corrective Retrieval Augmented Generation.The strategy we followed for this let’s say for each topic, we consult the book and identify relevant sections. Before forming an opinion, categorize the gathered information into three groups: **Correct**, **Incorrect**, and **Ambiguous**. Process each type of information separately. Then, based on this processed information, compile and summarize it mentally
How it works
- Retrieval Evaluator: A lightweight model assesses the relevance of retrieved documents to the input query, assigning a confidence score to each document. This evaluator is fine-tuned on datasets with relevance signals, allowing it to distinguish relevant documents from irrelevant ones, even if they share surface-level similarities with the query.
- Action Trigger: Based on the confidence scores, CRAG triggers one of three actions:
- Correct: If at least one document has a high confidence score, CRAG assumes the retrieval is correct and refines the retrieved documents to extract the most relevant knowledge strips.
- Example: If the query is “What is Henry Feilden’s occupation?” and a retrieved document mentions Henry Feilden’s political affiliation, CRAG would identify this as relevant and refine the document to focus on the information about his occupation.
- Incorrect: If all documents have low confidence scores, CRAG assumes the retrieval is incorrect and resorts to web search for additional knowledge sources.
- Example: If the query is “Who was the screenwriter for Death of a Batman?” and the retrieved documents do not contain the correct information, CRAG would initiate a web search using keywords like “Death of a Batman, screenwriter, Wikipedia” to find more reliable sources.
- Ambiguous: If the confidence scores are neither high nor low, CRAG combines both refined retrieved knowledge and web search results.
- Correct: If at least one document has a high confidence score, CRAG assumes the retrieval is correct and refines the retrieved documents to extract the most relevant knowledge strips.
- Knowledge Refinement: For relevant documents, CRAG employs a decompose-then-recompose approach:
- It breaks documents into smaller knowledge strips, filters out irrelevant strips based on their relevance scores, and then recomposes the remaining relevant strips into a concise knowledge representation.
- Web Search: When the initial retrieval fails, CRAG utilizes web search to find complementary information.
- It rewrites the input query into keyword-based search queries and prioritizes results from authoritative sources like Wikipedia to mitigate the risk of biases and unreliable information from the open web.
- The retrieved web content is then refined using the same knowledge refinement method.
Check out implementation from langchain here
Contextual Retrieval
Contextual Retrieval is a technique that enhances the accuracy of retrieving relevant information from a knowledge base, especially when used in Retrieval-Augmented Generation (RAG) systems. It addresses the limitations of traditional RAG, which often disregards context, by adding relevant context to the individual chunks of information before they are embedded and indexed. This process significantly improves the system’s ability to locate the most pertinent information.
- This technique applies the BM25 ranking function, which relies on lexical matching for finding specific terms or phrases, to the contextualized chunks.
- Contextual Retrieval leverages AI models like Claude to generate the contextual text for each chunk
- It required more window context model and space
Retrieval Interleaved Generation (RIG)
A technique devloped by google that enhances the factual accuracy of large language models (LLMs) by integrating structured external data into their responses.Unlike standard LLMs that rely solely on their internal knowledge, RIG dynamically retrieves data from a trusted repository like Data Commons.This allows RIG to provide more accurate and reliable information by leveraging real-time data.
How it works
-
Identifying the Need for External Data: The LLM recognizes when a query requires external information beyond its internal knowledge, distinguishing between general knowledge and specific data-driven facts.
-
Generating a Natural Language Query: Once external data is needed, the model generates a natural language query, designed to interact with a data repository like Data Commons, for example, “What was the unemployment rate in California in 2020?”
-
Fetching and Integrating Data: The model sends the query to Data Commons through an API, retrieves relevant data from diverse datasets, and seamlessly incorporates it into its response.
-
Providing a Verified Answer: The LLM uses the retrieved data to give a reliable, data-backed answer, reducing the risk of hallucinations and improving the trustworthiness of its output.
Chain-of-Retrieval Augmented Generation
Since most RAG datasets contain only the query (Q) and final answer (A), CoRAG generates intermediate retrieval chains using rejection sampling:
- The model samples a sequence of sub-queries (Q1, Q2, …, QL) and corresponding sub-answers (A1, A2, …, AL).
- A retriever fetches the top-k relevant documents for each sub-query.
- The model is trained to select the best retrieval chain using a log-likelihood scoring mechanism.
Example
-
Query → > Where did the star of Dark Hazard study?
-
Instead of doing a single retrieval step, CoRAG breaks the problem into smaller steps and retrieves information iteratively.
-
Since “Where did the star of Dark Hazard study?” is complex, CoRAG decomposes it into:
- Sub-query 1: _What was the name of the star of Dark Hazard
- _Retrieved Answer: Edward G. Robinson
-
Now, instead of guessing, CoRAG reforms the next query:
- Sub-query 2: Where did Edward G. Robinson go to college?
- Retrieved Answer: No relevant information found.
-
Since the retrieval failed, CoRAG tries a different way:
- Sub-query 3: What college did Edward G. Robinson attend?
- Retrieved Answer: City College of New York.
Graph RAG
For query-focused abstractive summarization
Knowledge Graphs: A knowledge graph is a specialized type of graph designed to represent knowledge and information in a structured way. It consists of:
- Nodes: These represent entities, such as people, places, events, or concepts. For example, in a knowledge graph about movies, nodes could represent individual films, actors, directors, or genres.
- Edges: These represent relationships between entities. For example, an edge labeled “directed” could connect a “director” node to a “movie” node, indicating that the director directed that particular film.
- Properties: These are key-value pairs associated with nodes and edges that provide additional information. For example, a “movie” node might have properties like “title”, “release date”, and “IMDb rating”.
Graph Databases: These are databases specifically designed to store and manage knowledge graphs. They offer advantages over traditional relational databases (RDBMS) when dealing with complex, interconnected data. The sources specifically focus on Neo4j, a popular graph database.
LightRAG
LightRAG achieves this by incorporating graph structures into text indexing and implementing a dual-level retrieval framework
Features an incremental update algorithm that seamlessly integrates new entities and relationships into the existing graph structure without the need for full reconstruction
HippoRAG
This framework draws inspiration from the hippocampal indexing theory of human long-term memory and aims to enhance knowledge integration in Large Language Models
HippoRAG utilizes the synergy between LLMs, knowledge graphs (KGs), and the Personalized PageRank (PPR) algorithm to emulate the roles of the neocortex and hippocampus in human memory
During retrieval, the LLM extracts key named entities (query named entities) from the user’s query, and these entities are linked to corresponding nodes (query nodes) in the KG. These query nodes serve as the starting points for the PPR algorithm.PPR operates by distributing a probability mass across the KG, starting from the query nodes. The algorithm simulates random walks across the graph, with the probability of transitioning to neighboring nodes influenced by the edge weights and connections.
Astute RAG
To solve the potential conflicts arise between the LLMs’ internal knowledge and external sources. let say what is captial of india? for this LLM answer will be new delhi but we added the context using RAG that has new york so there will be conflict to resolve this they introduced this method
How it works
- First Astute RAG prompts the LLM with the question and asks it to generate a passage based on its internal knowledge
- Astute RAG combines the generated passage with the retrieved ones using RAG, marking their sources.
- It might go through a few iterations, prompting the LLM to further refine the information by sending both context and asking for good one
Prompt for first step
Generate a document that provides accurate and relevant information to answer the given question. If the information is unclear or uncertain, explicitly state ’I don’t know’ to avoid any hallucinations. Question: {question} Document
Prompt for Iterative Knowledge Consolidation:
Consolidate information from both your own memorized documents and externally retrieved documents in response to the given question. * For documents that provide consistent information, cluster them together and summarize the key details into a single, concise document. * For documents with conflicting information, separate them into distinct documents, ensuring each captures the unique perspective or data. * Exclude any information irrelevant to the query. For each new document created, clearly indicate: Whether the source was from memory or an external retrieval.
The original document numbers for transparency.
Initial Context: {context}
Last Context: {context}
Question: {question}
New Context
Final prompt
Task: Answer a given question using the consolidated information from both your own
memorized documents and externally retrieved documents.
Step 1: Consolidate information
* For documents that provide consistent information, cluster them together and summarize the key details into a single, concise document.
* For documents with conflicting information, separate them into distinct documents, ensuring each captures the unique perspective or data.
* Exclude any information irrelevant to the query.For each new document created, clearly indicate:
* Whether the source was from memory or an external retrieval.
* The original document numbers for transparency.
Step 2: Propose Answers and Assign Confidence For each group of documents, propose a possible answer and assign a confidence score based on the credibility and agreement of the information.
Step 3: Select the Final Answer
After evaluating all groups, select the most accurate and well-supported answer.
Highlight your exact answer within <ANSWER> your answer </ANSWER>.
Initial Context: {context_init}
[Consolidated Context: {context}] # optional
Question: {question}
Answer:
Note: This method only work if LLM has some knoweledge about the question
HTML RAG
HtmlRAG is a system that uses HTML instead of plain text in Retrieval-Augmented Generation (RAG) systems, preserving structural and semantic information inherent in HTML documents. The system addresses the challenge of handling longer input sequences and noisy contexts presented by HTML by employing an HTML cleaning module to remove irrelevant content and compress redundant structures, followed by a two-step structure-aware pruning method. The first step prunes less important HTML blocks with low embedding similarities with the input query, and the second step conducts finer block pruning with a generative model.
RAG as service
Eyelevel
EyeLevel doesn’t use vector DBs like Pinecone at all. they use semantic objects
A semantic object contains:
- The original chunk of text
- Autogenerated metadata (e.g., section headers, doc origin)
- Two rewritten versions of the text:
- One optimized for search
- One optimized for completion This ensures the context is preserved, which is crucial for accurate answers.
When a user submits a query: - The system rewrites the query into a semantically aligned format. - Searches across the full semantic object: text, metadata, and rewritten search version. - A fine-tuned LLM ranks the results for maximum accuracy.
Over 9 fine-tuned models are used in the pipeline to optimize ingestion, retrieval, and ranking.
Resources
Frameworks and Toolkits for RAG (Retrieval-Augmented Generation):
- Pinecone Canopy: A framework built by Pinecone for developing vector-based applications.
- FlashRAG: A Python toolkit for efficient RAG research, designed to support retrieval-augmented generation use cases.
- RAGFlow: An open-source RAG engine focusing on deep document understanding for more advanced RAG applications.
Courses and Learning Resources:
- Introduction to RAG by Ben: Educational material to help understand the fundamentals and implementation of Retrieval-Augmented Generation (RAG).
- LLM Twin Course: A course focused on using twin architectures for RAG-based research and projects.
Research Repositories and Articles:
- RAG Techniques: A GitHub repository that compiles techniques, methods, and best practices for working with RAG systems.
- Beyond the Basics of RAG: Advanced topics and concepts for pushing the limits of RAG technology.
- Microsoft AutoGen**: A toolkit provided by Microsoft to automate the process of generating language models and leveraging RAG workflows.
- https://github.com/bRAGAI/bRAG-langchain Everything you need to know to build your own RAG application
Cache-Augmented Generation
CAG capitalizes on the extended context capabilities of modern LLMs by preloading all relevant documents into the model’s context window and caching the runtime parameters (Key-Value pairs). This approach entails
-
Preloading Knowledge: All pertinent documents are loaded into the LLM’s context window before inference
-
Caching Runtime Parameters: The model’s internal states (KV cache) are stored, encapsulating the inference state
-
Inference without Retrieval: During inference, the model utilizes the preloaded context and cached parameters to generate responses, eliminating the need for real-time retrieval
-
Elimination of Retrieval Latency
-
Reduction in Retrieval Errors
Gemini 2.5 Pro, with its 1 million-token (soon multi-million) context window, may make traditional RAG (Retrieval-Augmented Generation) unnecessary.
Instead of chunking documents, creating embeddings, and retrieving them from a vector database, a new method called CAG (Cache-Augmented Generation) just loads all relevant data directly into the context window and caches it for reuse.
Because context windows are huge, costs are falling, and models are faster, this approach is now practical. Recent studies (including Databricks and “Don’t do RAG”) show that long-context models outperform RAG in accuracy and speed, with fewer failure points and simpler setup.
RAG still makes sense when data changes constantly (e.g., live financial filings), but for most stable data, CAG + large context + prompt caching is simpler, faster, and more reliable.
NOTE: elevenlabs RAG using this apporach.
RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL
- Chunking: Split text into small segments (~100 tokens).
- Embedding: Turn chunks into vectors (SBERT).
- Clustering: Group semantically similar chunks (GMM + UMAP).
- Summarization: Use an LLM to create concise summaries of each cluster (~72% shorter).
- Recursion: Repeat embedding → clustering → summarization on the summaries, building multiple tree layers (leaf nodes = raw text, upper nodes = summaries).
Retrieval Strategies
- Tree Traversal: Start at the root, go down layer by layer selecting top-k nodes.
- Collapsed Tree (best): Flatten all layers, then retrieve the most relevant nodes across all levels until token budget is reached.
code here
Adaptive RAG
Adaptive RAG recognizes that different queries need different strategies. Simple factual questions don’t require the same computational overhead as complex analytical tasks.
- Classifies query complexity using a lightweight model
- Routes simple queries to direct answering
- Applies iterative retrieval for complex questions
- Uses single-step retrieval for moderate complexity
Code here
Agentic RAG
Eval in RAG
RAG Triad of metrics
- Context Relevance → is retervied context relvant to the query?
- Answer Relevance → is the response relvant to the query?
- Groundedness → is response supported by the context?
Mean Reciprocal Rank (MRR) - Measures how quickly the first relevant document appears in ranked results. Score of 1.0 if relevant doc is at rank 1, 0.5 if at rank 2, etc.
Normalized Discounted Cumulative Gain (nDCG) - Evaluates ranking quality by assigning higher importance to relevant documents at better positions, supporting graded relevance levels.
Precision@K and Recall@K - Precision@k measures the proportion of relevant documents in top-k results; Recall@k measures how many relevant documents were retrieved overall
Hit Rate - Simple binary metric: did any relevant document appear in top-k results?
Framework for eval trulens_eval
Ragas
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context.
Ragas Framework
Quotient AI
Quotient AI automates manual evaluations starting from real data, incorporating human feedback.
- Context Relevance
- Chunk Relevance
- Faithfulness
- ROUGE-L
- BERT Sentence Similarity
- BERTScore
Evaluating Chunking Strategies
Recall is a crucial metric for evaluating the effectiveness of a chunking strategy. It measures the proportion of relevant chunks retrieved in response to a query.
A high recall rate indicates that the chunking strategy is effectively capturing and representing the information in a way that allows for accurate retrieval.
Example:
Imagine a document has been chunked, and a query results in three relevant chunks. The retriever returns five chunks, but only two of those are the relevant ones. In this case:
-
Relevant elements = 3
-
Retrieved elements that are also relevant = 2
-
Therefore, Recall = (2/3) * 100% = 66%
CocoIndex and issue in RAG
- if we have RAG we have no way to update the content what changed and find a way to which one changed and update that
- When you switch embedding models (e.g.,
text-embedding-ada-002totext-embedding-3-small), old vectors are incompatible with queries embedded by the new model. When you change chunking strategy from fixed-size to semantic boundaries, every chunk ID changes.
The Solution: A Stateful Context Layer
The solution is to treat your vector index like a materialized view—a pattern borrowed from traditional databases. The architecture has three layers:
- Source Layer: Connectors to data sources (GitHub, S3, Notion, etc.), each exposing documents with unique identifiers
- State Layer: A tracking table that stores what has been indexed, how it was processed, and what outputs were produced
- Target Layer: Vector databases, knowledge graphs, or search indices—treated as derived stores that can be rebuilt from the state layer
- Compute a cryptographic hash (Blake2b, 128-bit) of each document’s content. Two documents with identical content produce identical fingerprints, regardless of filename or location. - Store a “receipt” for each source document—the list of target keys (vector IDs) it produced.
Two modes of change detection:
- Polling: At configurable intervals, scan sources for modified documents, then run reconciliation on changes only
- Change streams: Subscribe to push notifications (S3 events, PostgreSQL logical replication, Google Drive changes API) for near-real-time updates
- https://pashpashpash.substack.com/p/why-i-no-longer-recommend-rag-for
- RAG need lot of optimization we need proper chunking and other things cost will be increased
- instead we can effectively use the context let agent decide what it want by attaching tools and other thing it need
Cheat sheet