
Fine-Tuning & Alignment
│
├── Fine-Tuning Methods
│ │
│ ├── Full Fine-Tuning — Update ALL model parameters; highest quality ceiling
│ │ but requires massive compute and risks catastrophic forgetting
│ │
│ ├── Supervised Fine-Tuning (SFT) — Train on instruction-response pairs;
│ │ teaches model to follow instructions and produce useful outputs
│ │
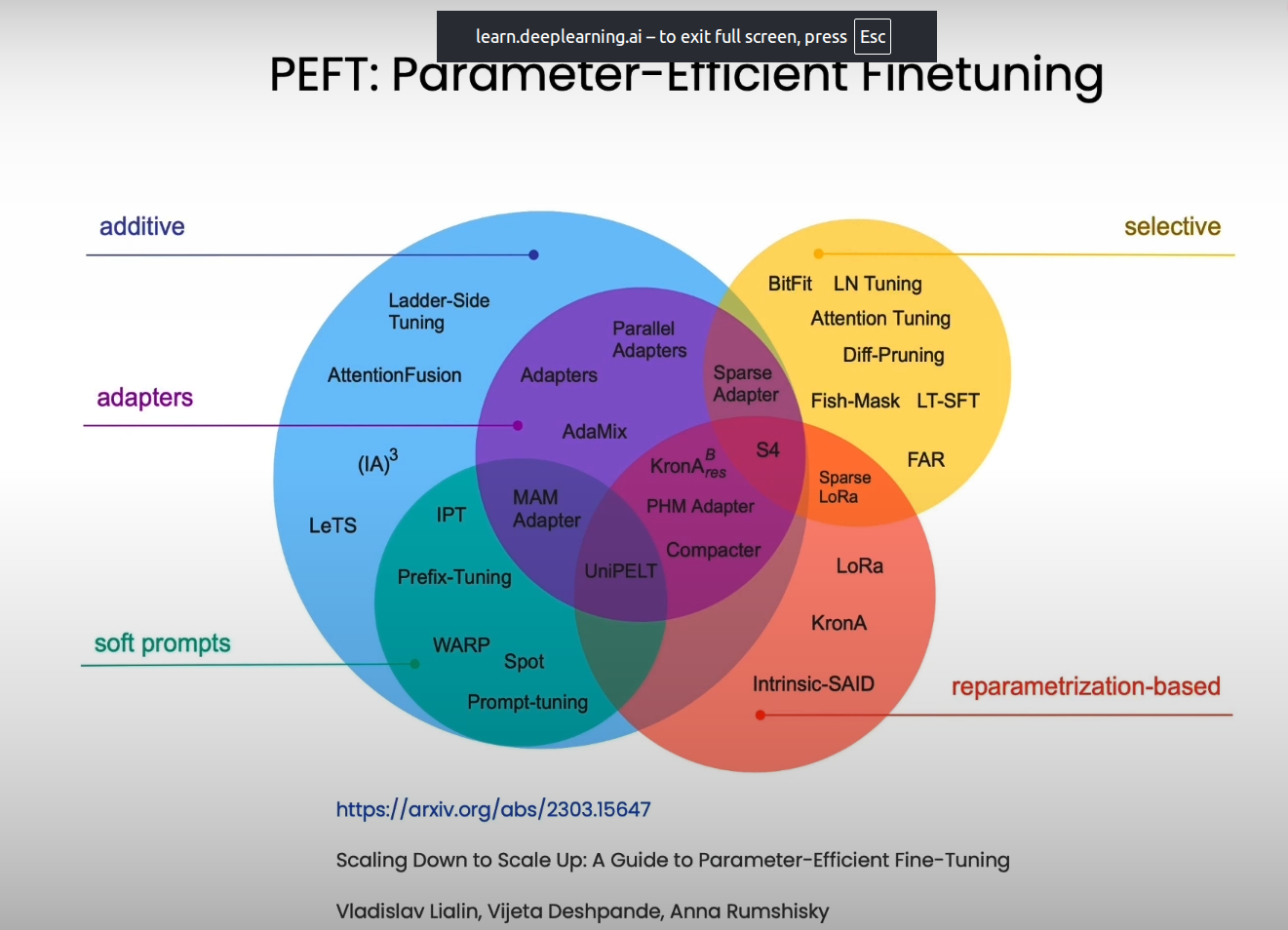
│ ├── Parameter-Efficient Fine-Tuning (PEFT)
│ │ ├── LoRA — Low-Rank Adaptation; injects small trainable matrices (rank r)
│ │ │ into attention layers; trains ~0.1% of parameters; most popular method
│ │ ├── QLoRA — LoRA + 4-bit quantization of base model; fine-tune 70B models
│ │ │ on a single 48GB GPU; best cost/quality tradeoff
│ │ ├── DoRA — Weight-Decomposed LoRA; separates magnitude and direction
│ │ │ updates for better convergence
│ │ ├── LongLoRA — Extends context length during fine-tuning efficiently
│ │ │ using shifted sparse attention
│ │ ├── Prefix Tuning — Prepends trainable virtual tokens to each layer;
│ │ │ ~0.1% parameters; good for generation tasks
│ │ ├── Prompt Tuning — Soft prompts: learnable embedding vectors prepended
│ │ │ to input; even lighter than prefix tuning
│ │ └── Adapter Layers — Small bottleneck layers inserted between transformer
│ │ blocks; original model frozen
│ │
│ ├── Instruction Tuning — Fine-tune on diverse instruction/response datasets
│ │ (FLAN, Alpaca, Dolly); teaches instruction-following behavior
│ │
│ └── Continued Pretraining — Further pretrain on domain corpus (medical,
│ legal, code) before SFT; adapts model knowledge to new domain
│
├── Alignment (Making Models Helpful, Harmless, Honest)
│ │
│ ├── RLHF (Reinforcement Learning from Human Feedback)
│ │ ├── Step 1: SFT — Supervised fine-tune on high-quality demonstrations
│ │ ├── Step 2: Reward Model Training — Train a model to score outputs
│ │ │ based on human preference rankings
│ │ ├── Step 3: PPO Optimization — Use Proximal Policy Optimization to
│ │ │ maximize reward while staying close to SFT policy
│ │ └── Limitations — Expensive, unstable RL, requires lots of human labels
│ │
│ ├── DPO (Direct Preference Optimization) — Skip reward model entirely;
│ │ directly optimize from preference pairs (chosen vs rejected);
│ │ simpler, more stable, and cheaper than RLHF
│ │
│ ├── GRPO (Group Relative Policy Optimization) — DeepSeek's method;
│ │ generates multiple outputs, uses rule-based scoring (math/code
│ │ correctness) instead of learned reward model; no critic needed
│ │
│ ├── KTO (Kahneman-Tversky Optimization) — Only needs binary good/bad
│ │ labels (not paired comparisons); easier data collection
│ │
│ ├── Constitutional AI (CAI) — Anthropic's approach: give model a
│ │ "constitution" of ethical principles; model self-critiques outputs
│ │ against these rules; no human labelers needed for safety training
│ │
│ ├── RLAIF (RL from AI Feedback) — Use AI (instead of humans) to
│ │ generate preference labels; scalable substitute for RLHF;
│ │ Google proved it matches human-labeled quality
│ │
│ └── Deliberative Alignment — Model learns explicit safety specs and
│ reasons over them at inference time; used in o1/o3 models
│
└── Fine-Tuning Tooling
├── Hugging Face PEFT — Library for LoRA, prefix tuning, adapters
├── Hugging Face TRL — Trainer for SFT, DPO, PPO with seamless LoRA support
├── Axolotl — Full-featured fine-tuning tool wrapping HF ecosystem
├── Unsloth — 2x faster LoRA fine-tuning with 80% less memory
└── OpenAI Fine-Tuning API — Managed SFT for GPT-3.5/4o models
Fine tunning
LoRA, QLoRA, DoRA, IA3, and BitFit
LORA
when we train a model with more weights it is time and resources consuming because we need to update the weights by loading on the machine which is hard so to avoid LORA introduce a low-rank matrix decomposition
Instead of updating all the weights, LoRA focuses on tracking the changes induced by fine-tuning and representing these changes in a compact form. It leverages low-rank matrix decomposition, which allows a large matrix to be approximated by the product of two smaller matrices.
Rank of matrics tell how many independt row present in a matrix
Example
Imagine a 5x5 matrix as a storage unit with 25 spaces. LORA breaks it down into two smaller matrices through matrix decomposition with “r” as rank(the dimension): a 5x1 matrix (5 spaces) and a 1x5 matrix (5 spaces). This reduces the total storage requirement from 25 to just 10, making the model more compact.
W = [[0.1, 0.2, 0.3, 0.4],
[0.5, 0.6, 0.7, 0.8],
[0.9, 1.0, 1.1, 1.2],
[1.3, 1.4, 1.5, 1.6]]
we freeze W and only train two small matrices: A and B.
Let’s say Rank = 2. Then:
Ais 4×2Bis 2×4
So instead of 16 parameters, you now train only 8 + 8 = 16 but with structured low-rank intent.
import numpy as np
# Original frozen weights
W = np.array([
[0.1, 0.2, 0.3, 0.4],
[0.5, 0.6, 0.7, 0.8],
[0.9, 1.0, 1.1, 1.2],
[1.3, 1.4, 1.5, 1.6]
])
# Trainable LoRA matrices (random for example)
A = np.random.randn(4, 2) # down projection
B = np.random.randn(2, 4) # up projection
# Scaled update (α = 2, rank = 2) => scale = α / rank = 1.0
scaling_factor = 1.0
delta_W = scaling_factor * (A @ B)
# Final weight = frozen + lora update
W_lora = W + delta_W
We can choose different LORA matrix rank example
W = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]] # Identity for simplicity
- Our weight 4*4
**LoRA with Rank = 1**
A = [[1],
[2],
[3],
[4]] # Shape: (4×1)
B = [[1, 0, -1, 0]] # Shape: (1×4)
**LoRA with Rank = 2**
A = [[1, 0],
[0, 1],
[1, 1],
[0, 0]]
B = [[1, 2, 0, 1],
[0, 1, 1, 0]]
import torch
import torch.nn as nn
class LoRALinear(nn.Module):
def __init__(self, in_features, out_features, r=4, alpha=1.0):
super().__init__()
# Original frozen weight
self.W = nn.Linear(in_features, out_features, bias=False)
self.W.weight.requires_grad = False
# LoRA matrices
self.A = nn.Linear(in_features, r, bias=False)
self.B = nn.Linear(r, out_features, bias=False)
# scaling
self.scale = alpha / r
def forward(self, x):
original = self.W(x)
lora_update = self.B(self.A(x)) * self.scale
return original + lora_updateWe start with:
Instead of updating (W), we do: Now replace: So:
Because:
- Pretrained model already learned general features
- Fine-tuning only needs small directional adjustments
So instead of:
“rewrite the entire brain”
We do:
“slightly rotate its representation space”
Low-rank = limited directions of change
Scaling factor (α / r)
Actual LoRA uses:
Why?
- If rank increases → more parameters → bigger updates
- Scaling keeps updates stable
How to choose which layer to update
- Query and Value projections (q_proj, v_proj): Most common, good default
- All attention projections (q, k, v, o): Better quality, more parameters
- Attention + FFN: Maximum adaptation, highest parameter count
So when after training we get seprate adpater
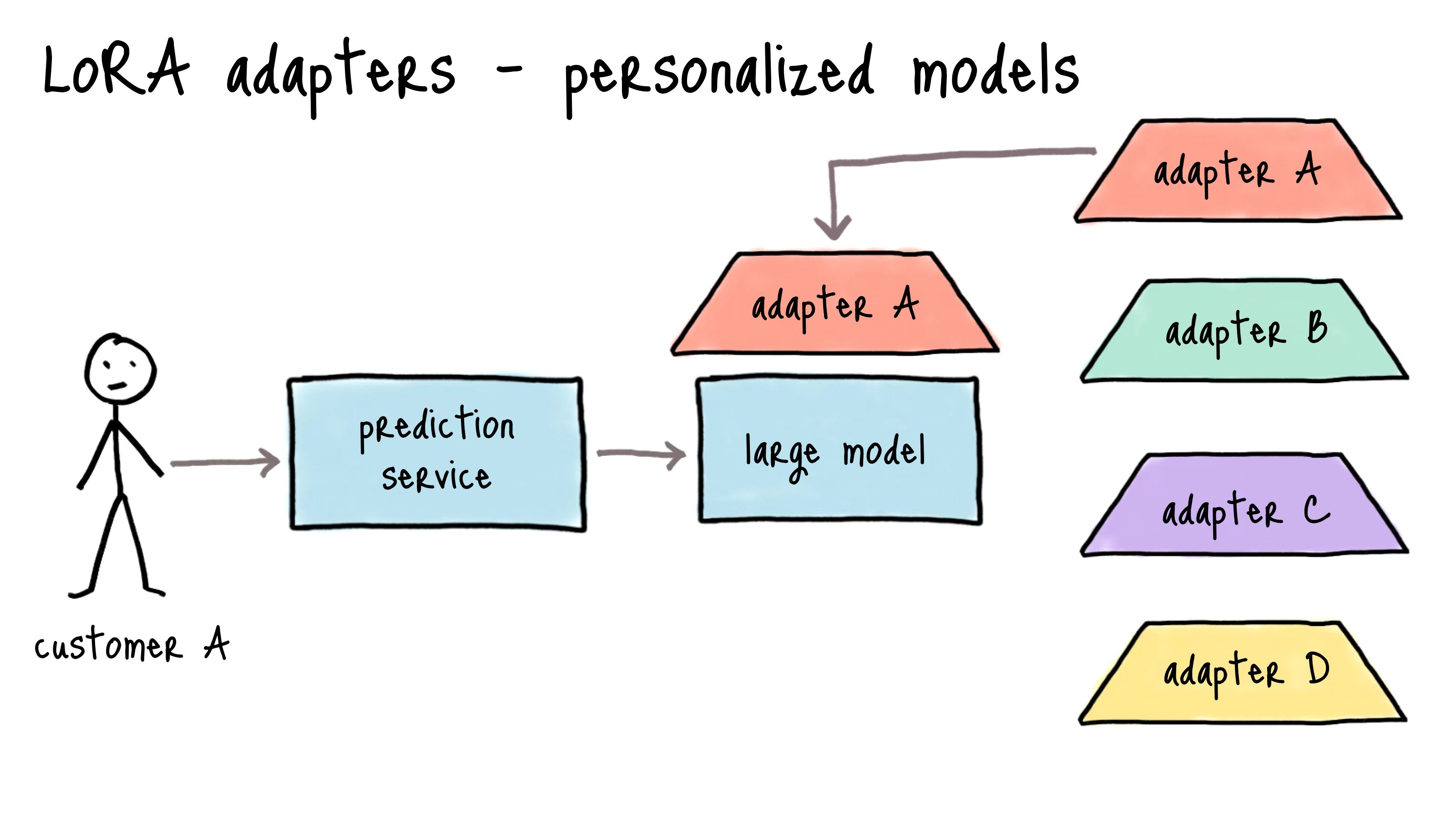
LoRA works by adding pairs of rank decomposition matrices to transformer layers, typically focusing on attention weights. During inference, these adapter weights can be merged with the base model, resulting in no additional latency overhead. LoRA is particularly useful for adapting large language models to specific tasks or domains while keeping resource requirements manageable.
After training with LoRA, you might want to merge the adapter weights back into the base model for easier deployment. This creates a single model with the combined weights, eliminating the need to load adapters separately during inference.
As illustrated above, the decomposition of ΔW means that we represent the large matrix ΔW with two smaller LoRA matrices, A and B. If A has the same number of rows as ΔW and B has the same number of columns as ΔW, we can write the decomposition as ΔW = AB. (AB is the matrix multiplication result between matrices A and B.)
How much memory does this save? It depends on the rank r, which is a hyperparameter. For example, if ΔW has 10,000 rows and 20,000 columns, it stores 200,000,000 parameters. If we choose A and B with r=8, then A has 10,000 rows and 8 columns, and B has 8 rows and 20,000 columns, that’s 10,000×8 + 8×20,000 = 240,000 parameters, which is about 830× less than 200,000,000.
Of course, A and B can’t capture all the information that ΔW could capture, but this is by design. When using LoRA, we hypothesize that the model requires W to be a large matrix with full rank to capture all the knowledge in the pretraining dataset. However, when we finetune an LLM, we don’t need to update all the weights and capture the core information for the adaptation in a smaller number of weights than ΔW would; hence, we have the low-rank updates via AB.
How To Avoid Overfitting?
Generally, a larger r can lead to more overfitting because it determines the number of trainable parameters. If a model suffers from overfitting, decreasing r or increasing the dataset size are the first candidates to explore. Moreover, you could try to increase the weight decay rate in AdamW or SGD optimizers, and you can consider increasing the dropout value for LoRA layers.
The QLoRA paper tested rank values from 8 to 256 and found:
“If LoRA is applied to all layers, the rank has little to no effect on downstream performance.”
- Because many tasks don’t need complex updates the pre-trained model already “knows” most things, and you’re just nudging it.
Alpha Alpha determines a scaling factor applied to the weight changes before they are added to the original model weights14. This factor is calculated as Alpha divided by Rank
Dropout
Dropout is a percentage that randomly sets some parameters to zero during training16. Its purpose is to help avoid overfitting, where the model performs well only on its training data but poorly on new, unseen data
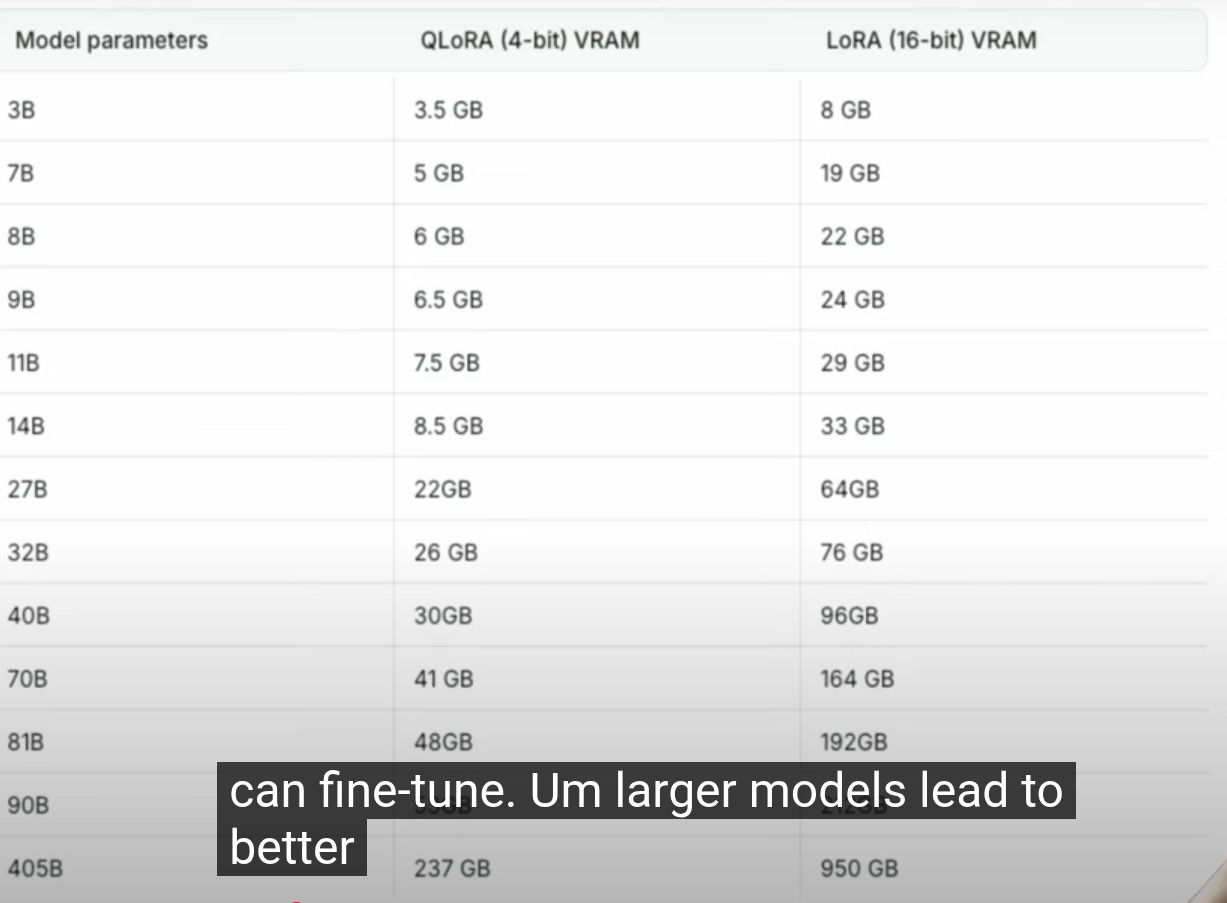
Parameters and there RAM required
QLORA
In this we just quantization matrix value from 32 bit to 8 Bit
LoRA:
- Introduce two low-rank matrices, A and B, to work alongside the weight matrix W.
- Adjust these matrices instead of the behemoth W, making updates manageable.
LoRA-FA (Frozen-A):
- Takes LoRA a step further by freezing matrix A.
- Only matrix B is tweaked, reducing the activation memory needed.
VeRA:
- All about efficiency: matrices A and B are fixed and shared across all layers.
- Focuses on tiny, trainable scaling vectors in each layer, making it super memory-friendly.
Delta-LoRA:
- A twist on LoRA: adds the difference (delta) between products of matrices A and B across training steps to the main weight matrix W.
- Offers a dynamic yet controlled approach to parameter updates.
LoRA+:
- An optimized variant of LoRA where matrix B gets a higher learning rate. This tweak leads to faster and more effective learning.
Resources
- LLORA for finetuning
- Fine tune LLMs 2024
- A collection Fine-Tuning video courses
- https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms
Aligment with human feedback
- RLHF
- DPO
- RLAIF
Axolotl
Is wrapper above hugging face and provides numerous example configuration files in YAML format, covering a variety of common use cases and model types.
- Supports fullfinetune, lora, qlora, relora, and gptq
- Customize configurations using a simple yaml file or CLI overwrite
base_model: codellama/CodeLlama-7b-hf
model_type: LlamaForCausalLM
tokenizer_type: CodeLlamaTokenizer
load_in_8bit: true
load_in_4bit: false
strict: false
datasets:
- path: mhenrichsen/alpaca_2k_test
type: alpaca
dataset_prepared_path:
val_set_size: 0.05
output_dir: ./outputs/lora-out
sequence_len: 4096
sample_packing: true
pad_to_sequence_len: true
adapter: lora
lora_model_dir:
lora_r: 32
lora_alpha: 16
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
wandb_project:
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 4
micro_batch_size: 2
num_epochs: 4
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
s2_attention:
warmup_steps: 10
evals_per_epoch: 4
saves_per_epoch: 1
debug:
deepspeed:
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
bos_token: "<s>"
eos_token: "</s>"
unk_token: "<unk>"LLM fine tuning made easy https://axolotl.ai/
Methods
Unsloth
Unsloth is a lightweight library for faster LLM fine-tuning
Check here it easy https://github.com/Mandark-droid/LFM2.5-1.2B-Instruct-mobile-actions/blob/main/train.py
finetune https://www.clarifai.com/
Lamini
Ray train
https://docs.ray.io/en/latest/train/train.html?_gl=1*fhc3w3*_gcl_au*MTk4OTE5MzY1Ni4xNzM0ODU1MTA0
https://openpipe.ai/
Train higher-quality, faster models that continuously improve.
https://www.tensorzero.com/ [very nice need to chck]
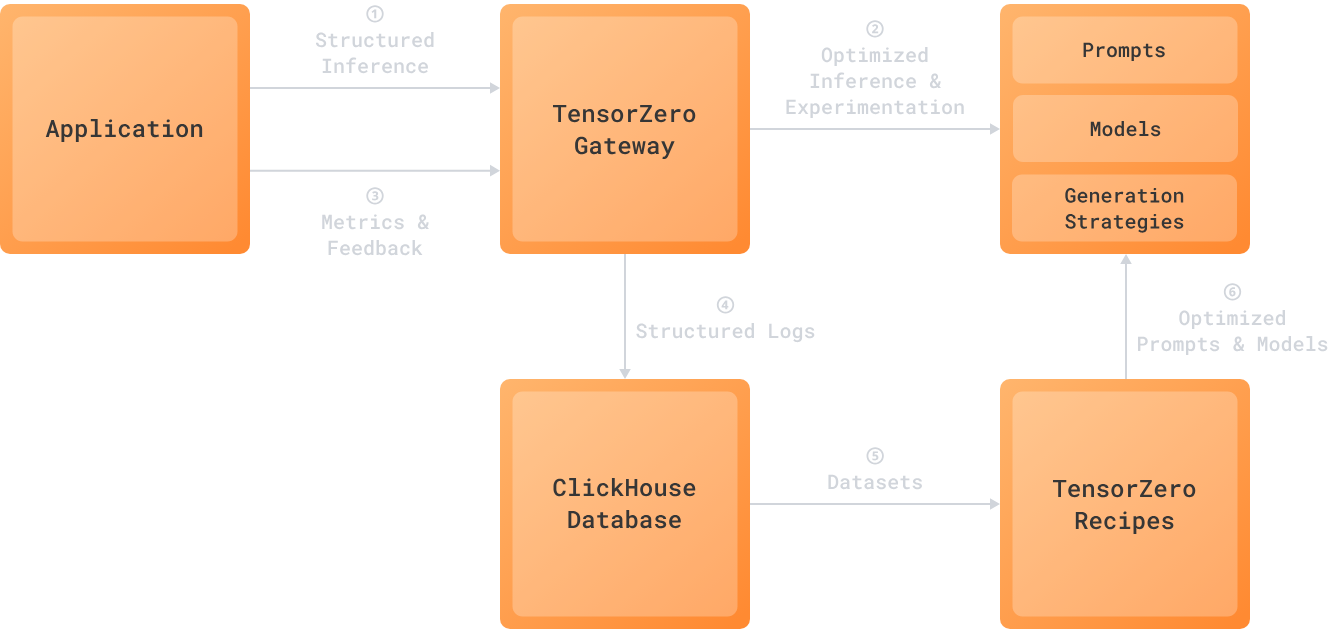
OpenPipe for fine-tuning and OctoAI for deployment
Posttrain finetune
- Huggingface TRL
- Open RLHF
- veRL
- nemo RL
Supervised finetunning
Labled prompt paris
- Input Sequence: Prompt + response (e.g., “Translate to French: Hello! Bonjour!“)
- Tokenization: Sequence is tokenized into IDs.
- Labels:
- Prompt tokens: Set to
-100to ignore them. - Response tokens: Set to their actual token IDs to guide the model in learning the correct output.
- Prompt tokens: Set to
- Prediction: The model predicts the next token at each position.
- For prompt tokens: The model is not penalized.
- For response tokens: The model is penalized based on how far its prediction is from the correct token.
- Loss Calculation: Loss is only calculated for response tokens, comparing predicted vs. actual tokens.
- Backpropagation: Model weights are updated based on the loss from the response tokens.
Example
combine prmpt with answer
`"Translate to French: Hello! Bonjour!"`
we pass the whole to LLM it will start predciting what by reading
tranlate and so on we will start seeing does it predict correctly the next token but we ingore that check for question we only do check for answer
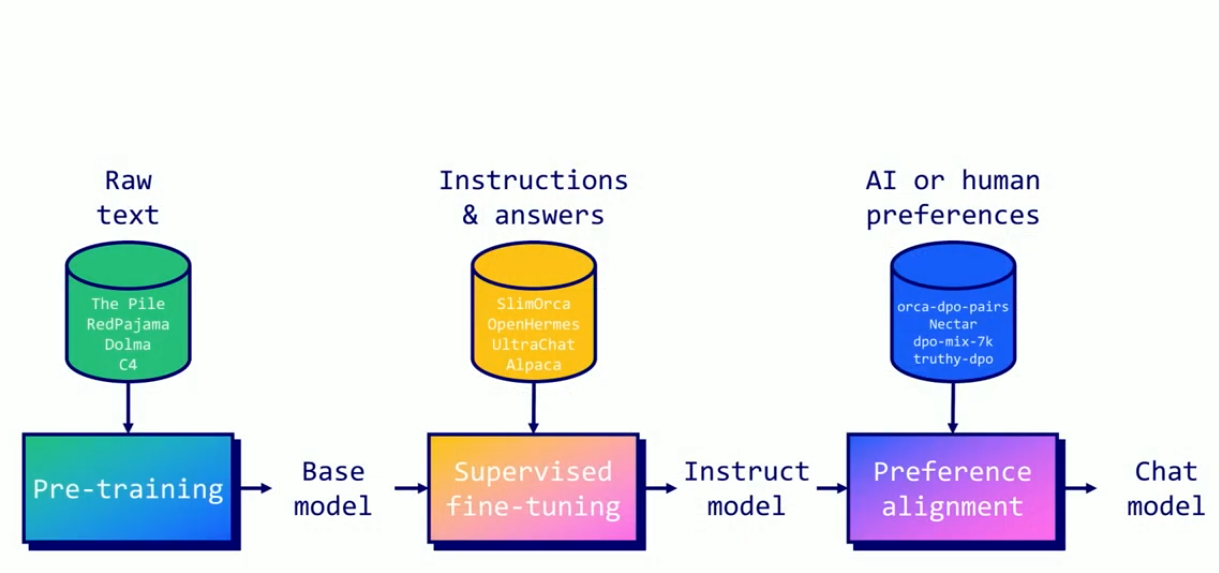

Preference Alignment
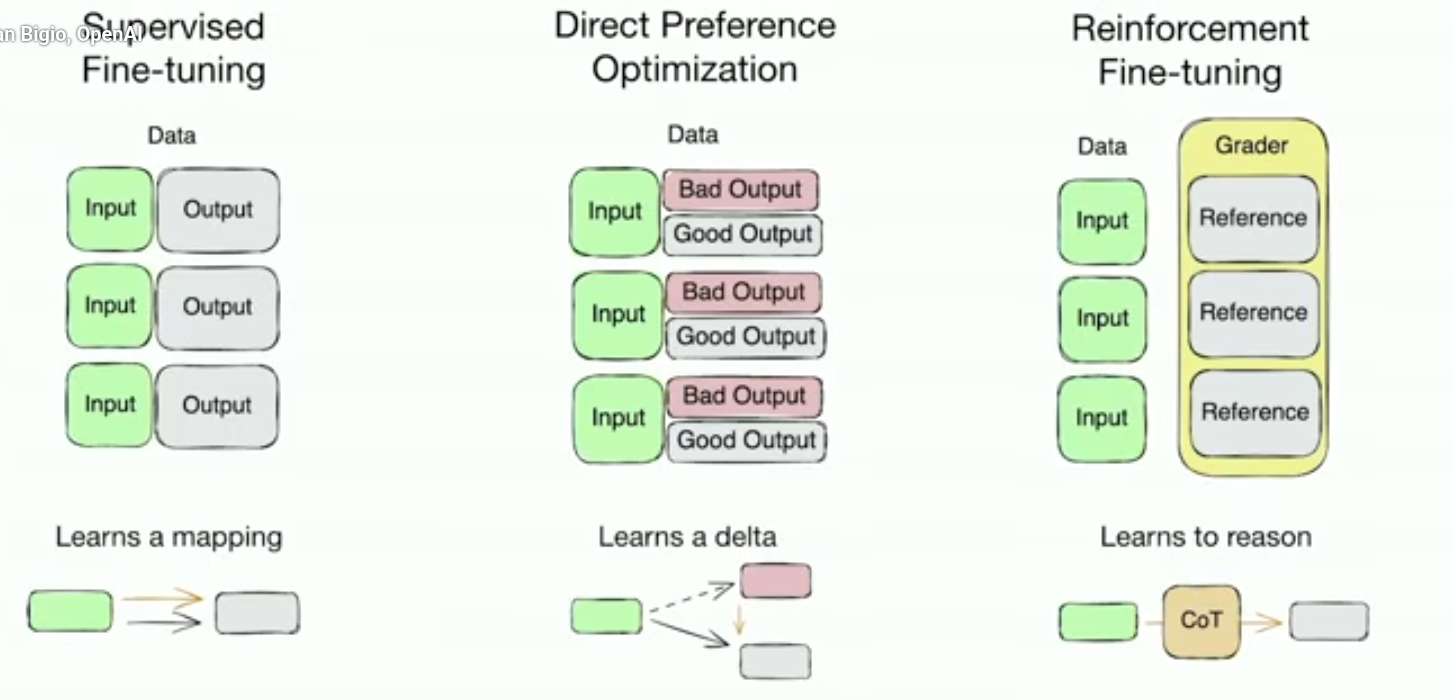
While supervised fine-tuning (SFT) teaches models to follow instructions and engage in conversations, preference alignment takes this further by training models to generate responses that match human preferences. It’s the process of making AI systems more aligned with what humans actually want, rather than just following instructions literally. In simple terms, it makes language models better for applications in the real world.
- Direct Preference Optimization (DPO)
DPO
Direct Preference Optimization (DPO) revolutionizes preference alignment by providing a simpler, more stable alternative to Reinforcement Learning from Human Feedback (RLHF). Instead of training separate reward models and using complex reinforcement learning algorithms, DPO directly optimizes language models using human preference data.
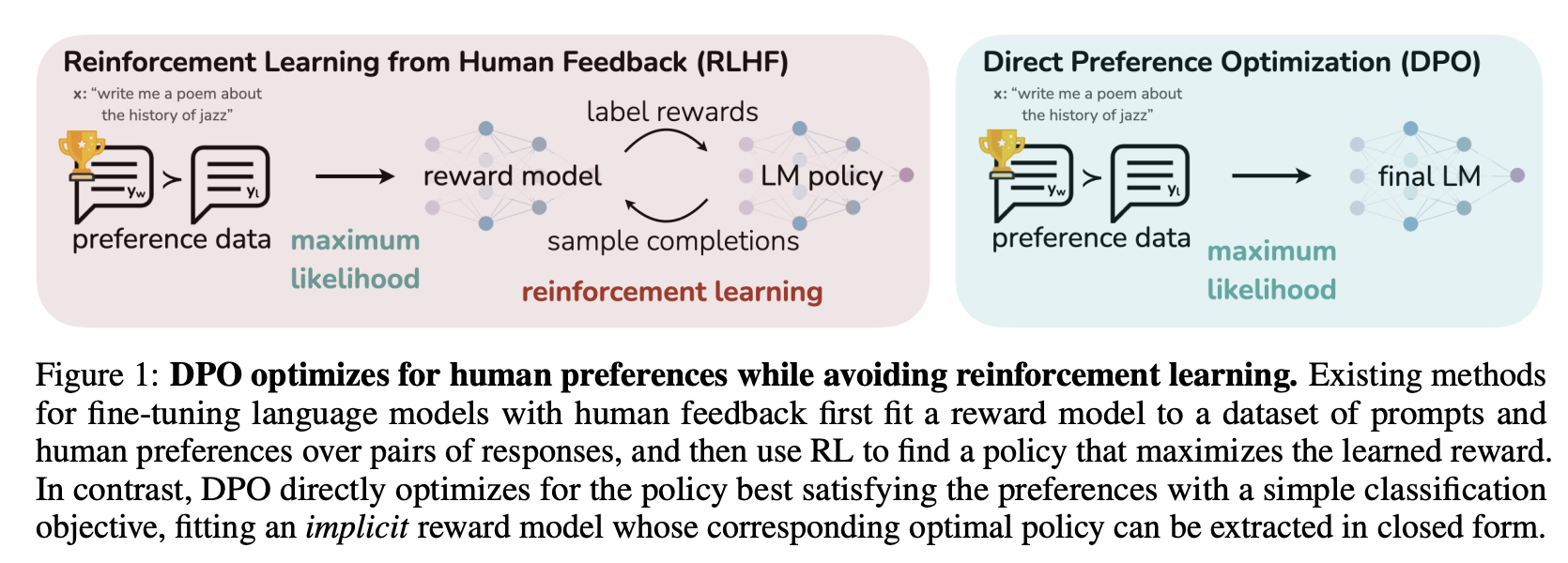
Traditional RLHF approaches require multiple components and training stages. As the diagram shows, it involves:
- Training a reward model to predict human preferences based on preferred and rejected responses.
- Using reinforcement learning algorithms like PPO to optimize the policy against the reward model.
DPO simplifies this process dramatically by skipping the reward model and using a binary cross-entropy loss to directly optimize the language model.
- First, training a SFT model to follow instructions.
- Then, training a DPO model to directly optimize the language model using preference data itself.
How DPO Works
DPO recasts preference alignment as a classification problem. Given a prompt and two responses (one preferred, one rejected), DPO trains the model to increase the likelihood of the preferred response while decreasing the likelihood of the rejected response.
Training Process
The DPO process requires supervised fine-tuning (SFT) to adapt the model to the target domain. This creates a foundation for preference learning by training on standard instruction-following datasets. The model learns basic task completion while maintaining its general capabilities.
Next comes preference learning, where the model is trained on pairs of outputs - one preferred and one non-preferred. The preference pairs help the model understand which responses better align with human values and expectations.
The core innovation of DPO lies in its direct optimization approach. Rather than training a separate reward model, DPO uses a binary cross-entropy loss to directly update the model weights based on preference data. This streamlined process makes training more stable and efficient while achieving comparable or better results than traditional RLHF.
The DPO Loss Function
The core innovation of DPO lies in its loss function, which directly optimizes the policy (language model) using preference
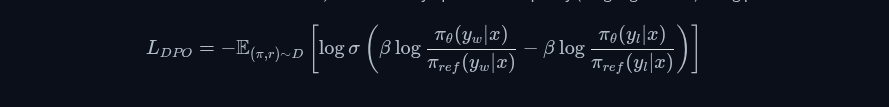
Where:
π_θis the model being trainedπ_refis the reference model (usually the SFT model)y_wis the preferred (winning) responsey_lis the rejected (losing) responseβis a temperature parameter controlling optimization strengthσis the sigmoid function
Model merging
Merege two model parameters by taking average
| Method | Parameters Updated | Memory Use | Best For | Drawbacks |
|---|---|---|---|---|
| Full FT | 100% | Very high repovive | Highest accuracy | GPU-intensive linkedin |
| LoRA | ~0.1% | Low arxiv | General PEFT | Slight quality drop apxml |
| QLoRA | ~0.1% (quantized) | Very low modal | Resource-limited setups | Quantization overhead geeksforgeeks |
| DoRA | ~0.1% | Low pravi | Improved PEFT quality | Newer, less tested encora |
| RLHF | Varies (often PEFT) | High ibm | Alignment/safety | Needs human feedback geeksforgeeks |
| Method | Reward Model? | Data Needed | Compute vs RLHF | Best For |
|---|---|---|---|---|
| DPO | No hyper | Preference pairs | Much lower youtube | Stable alignment |
| ORPO | No premai | Task + pairs | Single stage | End-to-end training |
| KTO | No snorkel | Labels only | Lowest data | Quick experiments |
| PPO (RLHF) | Yes | Pairs + rankings | High pelayoarbues | High-fidelity needs |
Online reinforcement learning
MUST NEED TO WATCH
- https://www.youtube.com/watch?v=uLrOI65XbDw Everything you need to know about Fine-tuning and Merging LLMs: Maxime Labonne
- https://www.youtube.com/watch?v=t1caDsMzWBk LoRA & QLoRA Fine-tuning Explained In-Depth
- https://www.youtube.com/watch?v=eC6Hd1hFvos Fine-tuning Large Language Models (LLMs) | w/ Example Code
- https://www.builder.io/blog/fine-tune-llm?ref=dailydev
- LoRA Without Regret
- https://www.youtube.com/watch?v=JfaLQqfXqPA
- What Small Language Model Is Best for Fine-Tuning
NOtes: If we finetune the model it will good the finetuned data but if we add handle new case like only 2 new case we need to finetune whole model again with all data include old and new data
Product
Distil labs provides a platform for training task-specific small language models (SLMs) with just a prompt and a few dozen examples. Our platform handles the complex machine learning processes behind the scenes
Has free