
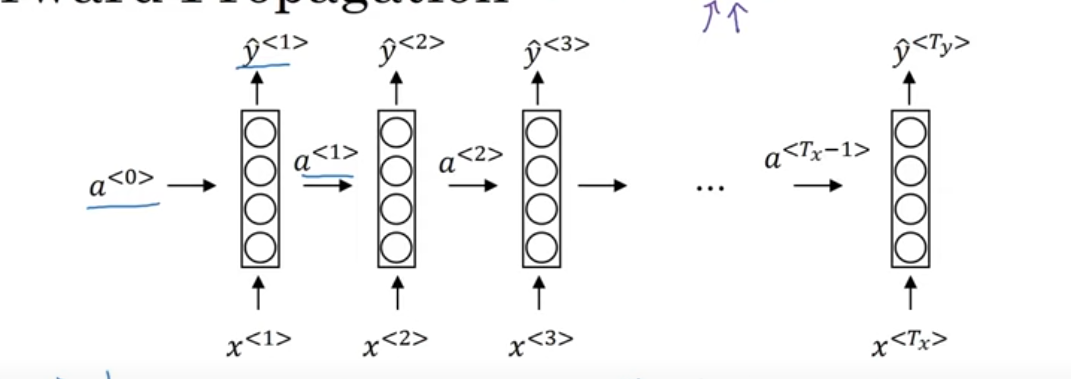
Forward Propagation in an RNN
In a Recurrent Neural Network (RNN), forward propagation is the process where the network takes an input sequence, passes it through its layers, and produces an output sequence. Here’s how it works:
Basic RNN Setup
- Input data: At each time step, you have an input , which is a vector (could be a word, a number, etc.).
- Hidden state: The RNN has a hidden state , which “remembers” information from previous time steps. This hidden state is updated at each time step based on the previous hidden state and the current input.
- Output: The RNN also produces an output at each time step.
The Key Equations in RNN Forward Propagation:
1. Hidden State Update
At each time step , the hidden state is updated using the previous hidden state and the current input .
Here:
- : Weight matrix that connects the previous hidden state to the current hidden state.
- : Weight matrix that connects the current input to the current hidden state.
- : Bias term added to the hidden state calculation.
- : Activation function (like tanh or ReLU) applied to the weighted sum. It helps the RNN model learn complex relationships.
What’s Happening Here:
- The previous hidden state contains information about the past (the history), and we combine it with the current input to compute the new hidden state .
- The weights and control how much of the previous state and the current input should influence the new hidden state.
- The activation function introduces non-linearity, which helps the model learn more complex patterns.
2. Output Calculation
Once we compute the hidden state for a given time step, we then calculate the output at that time step.
Here:
- : Weight matrix that connects the hidden state to the output.
- : Bias term for the output.
- : Activation function (like softmax for classification tasks or sigmoid for binary classification).
What’s Happening Here:
- The output is calculated by applying the weight matrix to the current hidden state .
- The output layer’s activation function ensures that the output has the right scale (e.g., for classification, softmax gives probabilities).
Vector repersentation of Hidden state and output
Hidden State Update:
In vector form:
- we combine the weight and a to single vector
Output Calculation:
In vector form:
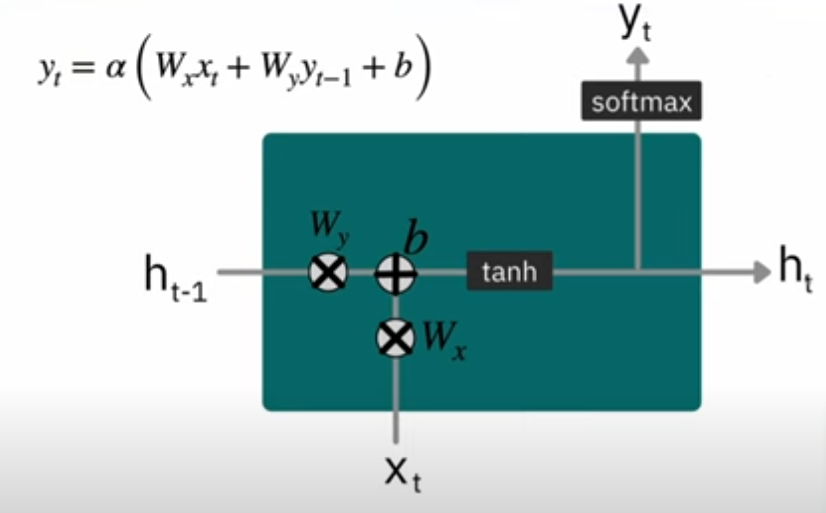
Back Propagation in an RNN
Forward pass: First, we compute the output using the forward propagation formulas.
Loss function: After computing the predicted output y^(t)\hat{y}^{(t)}y^(t), the loss is calculated (e.g., cross-entropy loss). This loss is then propagated back through the network.
Backward pass: Compute the gradients of the weights with respect to the loss. This requires applying the chain rule for each time step ttt in the sequence. The gradients are then used to update the weights.
Backpropagation Through Time (BPTT) in RNN
In an RNN, backpropagation is the process used to optimize the weights by adjusting them based on the error between the predicted output and the actual output . The idea is to propagate the error backward through the network, layer by layer, to update the weights. This process can be extended to sequences, and that’s called Backpropagation Through Time (BPTT).
Loss function
We calculate the loss to see how wrong our predictions are. Typically, for classification problems, we use cross-entropy loss:
Where:
- is the loss at time step .
- is the actual value (ground truth).
- is the predicted output from the RNN.
1. Gradient of the Output Layer:
For each time step , the gradient of the loss with respect to the predicted output is computed.
This is the difference between the predicted output and the actual output, which will be propagated back to update the weights.
2. Gradient of the Hidden Layer:
Now, we need to compute the gradient of the loss with respect to the hidden state . To do this, we use the chain rule, considering that the hidden state is influenced by the previous hidden state and the current input .
We compute the gradient of the loss at each time step with respect to :
Since the output is a function of , we apply the chain rule:
Thus, the gradient for the hidden state becomes:
3. Gradient of the Hidden State Update:
Now, we compute the gradient of the loss with respect to the weights , , and the bias involved in the update rule for the hidden state .
To do this, we apply the chain rule considering that the hidden state at time step depends on the previous hidden state and the input .
We start by computing the gradient with respect to :
The hidden state update equation is:
Therefore, the derivative with respect to is:
Where is the derivative of the activation function.
4. Updating the Weights and Biases:
The gradients computed above allow us to update the weights using gradient descent. The updates for the weights and biases at time step are as follows:
- For the weights between the hidden state and the output:
Where is the learning rate.
- Similarly, for the weights and , and the biases and , the gradients are computed and the weights are updated accordingly.
Question i have is
- i need to write this one step by hand one time to fully understand
Types of RNN
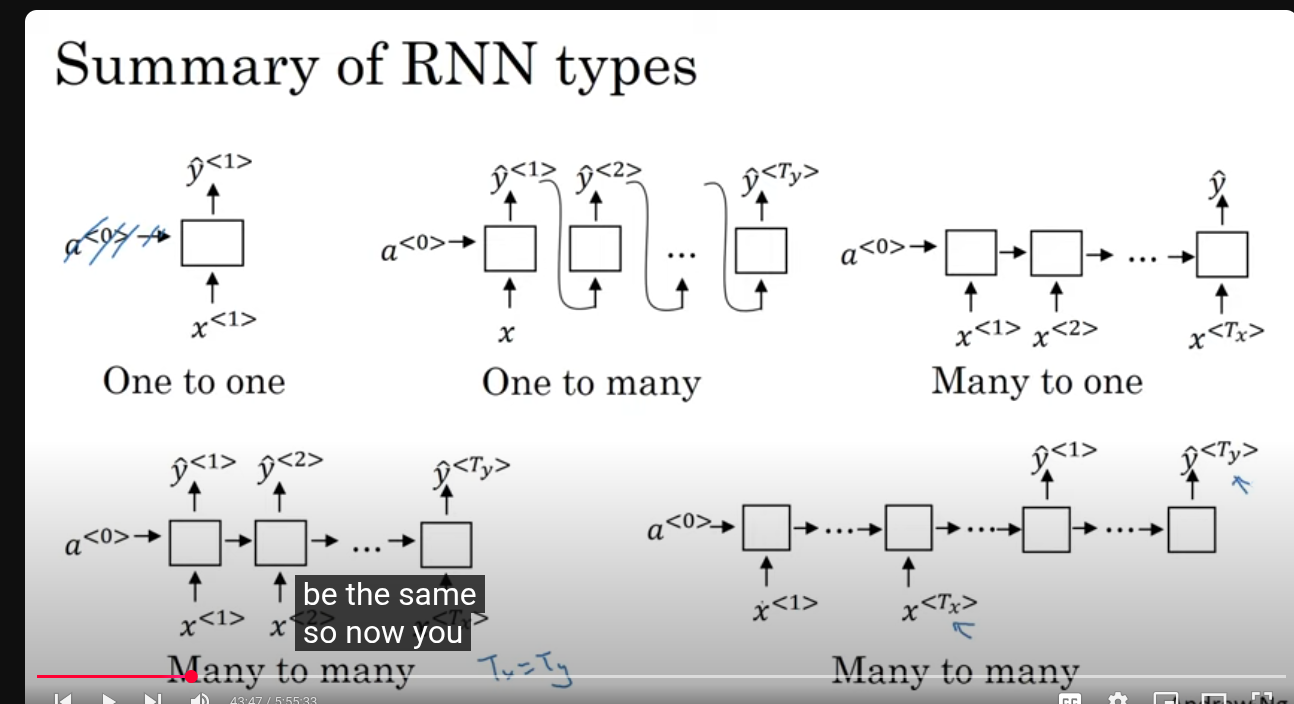
1. One to One
- Diagram: One input gives one output .
- Example: A regular feedforward neural network (no sequence).
- Use case: Basic classification or regression tasks where input and output are single data points (e.g., image classification).
2. One to Many
- Diagram: One input produces many outputs .
- Example: Image captioning.
- Explanation: You give one input (an image), and the model generates a sequence of outputs (a sentence describing the image).
- Why use? When a single input corresponds to multiple outputs over time.
3. Many to One
- Diagram: Many inputs produce one output .
- Example: Sentiment analysis.
- Explanation: The model reads a whole sequence (like a sentence) and outputs one single prediction (e.g., positive or negative sentiment).
- Why use? When you want to summarize or classify an entire input sequence with one output.
4. Many to Many (Equal length inputs and outputs)
- Diagram: Many inputs produce many outputs , where .
- Example: Part-of-speech tagging.
- Explanation: The model reads a sequence and outputs a sequence of the same length (e.g., each word gets tagged).
- Why use? When you want to generate an output for every input element.
5. Many to Many (Different length inputs and outputs)
-
Diagram: Many inputs produce many outputs , but .
-
Example: Machine translation (English sentence to French sentence).
-
Explanation: Input and output sequences are both variable length but not necessarily equal.
-
Why use? For tasks where input and output lengths differ but both are sequences.
Building Next word prediction model
Given a sequence of words, we want the RNN to learn how to predict the next word.
For example:
“Cats average 15 hours of sleep a day.”
We want the model to learn to predict:
- After “Cats” → “average”
- After “Cats average” → “15”
- After “Cats average 15” → “hours”
- Finally, predict the end of sentence:
<EOS>
1. Inputs and Outputs in Time Steps
Each time step in an RNN receives:
- Input : A word (converted into a word vector).
- Hidden state : Stores memory from the previous time steps.
- Output : The prediction (probability distribution over vocabulary for the next word).
2. First Time Step
- : Initial hidden state is zero.
- : The special “start-of-sentence” token.
- Output: : Predicted probability of first word.
- Example: P(cats), P(dogs), P(the), etc.
- Suppose the correct word is “Cats” → loss compares to “Cats”
3. Second Time Step
- : Feed previous actual word.
- : Computed from and
- Output : Predicts the next word (like “average”)
4. Third Time Step
- Hidden state updates to
- Output : Predicts “15”
5. This Continues Until <EOS>
- Eventually, it predicts the final word →
<EOS>(end of sentence)
Loss Function
The loss measures how well the model’s predicted word distribution matches the actual next word.
For a single time step:
- This is cross-entropy loss
- is the true word (one-hot encoded)
- is the predicted probability for that word
For the whole sentence:
- Sum the loss over every word in the sequence.
In Training vs. Inference
During training:
- The input at each step is the true previous word (teacher forcing).
- So:
During inference (prediction):
- The input is the model’s own predicted word from the previous step:
Vanishing Gradients
The vanishing gradient problem occurs when the gradient values become extremely small during backpropagation, specifically as information flows backward through many layers or time steps. This is similar to what happens in very deep standard neural networks
Gated Recurrent Units
GRUs are a modification to the basic RNN hidden layer designed to address the vanishing gradient problem and improve the capture of long-range connections
we will have two new state
- Reset Gate: Determines how much of the previous memory should be ignored when computing the candidate state.
- Update Gate: Controls how much of the new candidate state should replace the old memory.
Vector notation
Candidate Hidden State:
Update Gate:
Reset Gate:
Final Hidden State:
GRU_RNN
Exploding Gradients
Exploding gradients are the opposite problem, where gradients grow exponentially during backpropagation
large gradients can cause neural network parameters to become extremely large and unstable, leading to numerical overflow (e.g., resulting in “Not a Number” or NaN values)
Exploding gradients are generally easier to detect and address than vanishing gradients. The common solution is gradient clipping, which involves rescaling gradient vectors if their magnitude exceeds a certain threshold
LSTM
In a vanilla RNN the recurrence:
When we train through many time steps, gradients get multiplied repeatedly by weights and activations.
-
If the multipliers < 1 → gradients shrink → vanishing gradient.
-
If multipliers > 1 → gradients blow up → exploding gradient.
Result:
- RNNs can’t remember dependencies from far back in the sequence.
- They “forget” old context.
“How do we let a neural network decide what to remember and what to forget over long time scales?”
The answer: give the network a separate memory track (called the cell state ) that can carry information along mostly unchanged, with small updates.
Think of it like:
- = short-term working memory.
- = long-term storage, guarded by gates.
The gates in LSTM
An LSTM cell introduces three main gates (all are tiny neural nets with sigmoid activations, values between 0 and 1):
- Forget gate:
Decides which parts of the old cell state to keep vs. forget.
(If , that info is erased; if , it’s kept.)
- Input gate:
Decides which new info should enter memory.
Alongside, a candidate memory is created:
- Update cell state:
(Forget some of the past, add some of the new.)
- Output gate:
Then the hidden state is updated as:
So the full LSTM cell has: forget gate, input gate, output gate, and a cell state pipeline.
Unfolding an LSTM
Like an RNN, you still unfold it over time:
x1 → [LSTM Cell] → h1, c1
x2 → [LSTM Cell] → h2, c2
x3 → [LSTM Cell] → h3, c3
But now, each cell has two highways:
-
The hidden state (short-term).
-
The cell state (long-term).
The gates let information survive many steps without vanishing, because can be passed forward almost unchanged if gates allow it.
FLow
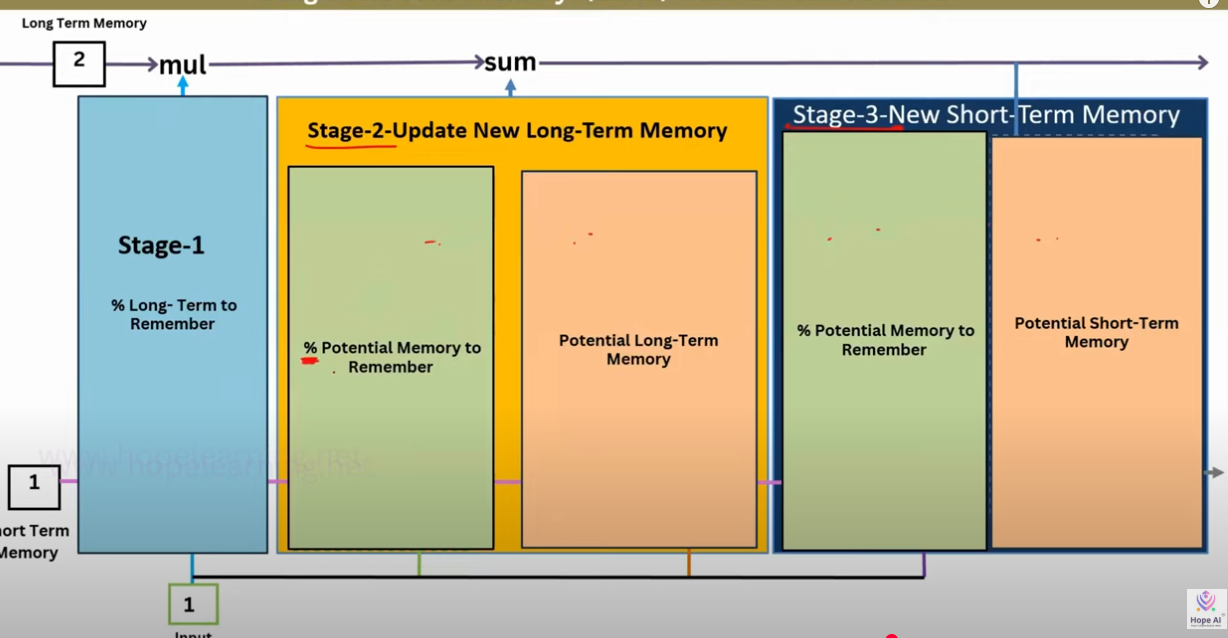
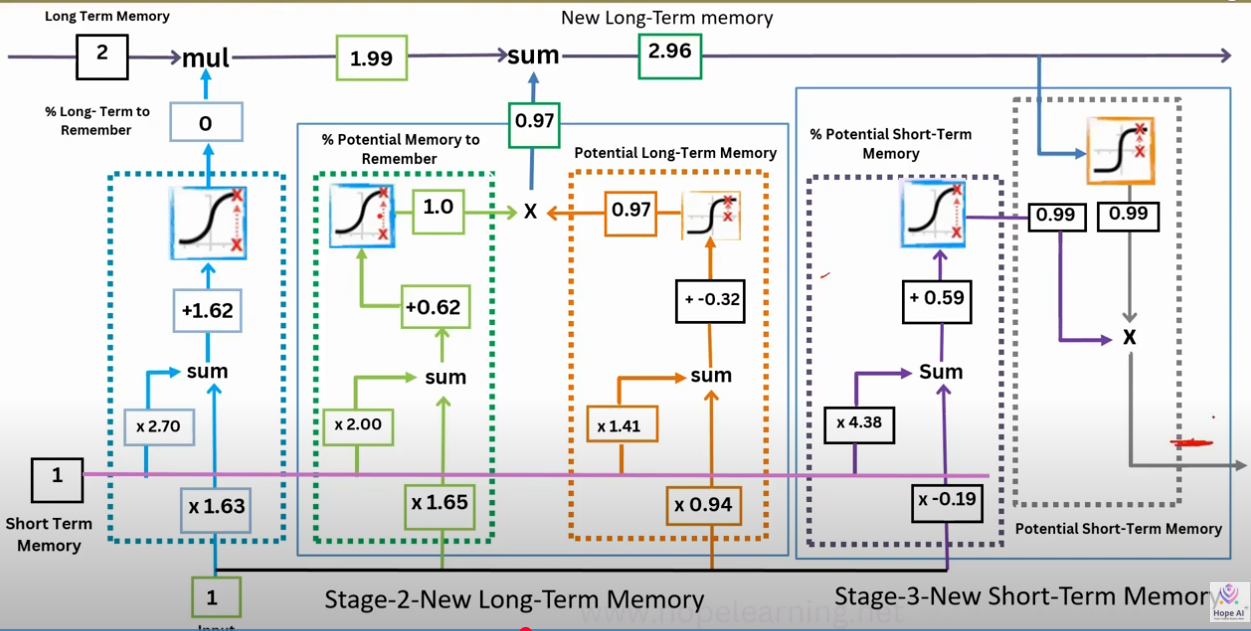
Stage 1: Forgetting (Filter Old Long-Term Memory)
- Input: previous cell state () = long-term memory up to now.
- Gate: Forget gate .
- Operation: multiply old memory by .
- If : keep everything.
- If : erase completely.
- Usually, it’s a fraction in between.
Interpretation: “How much of the past memory should I carry forward?”
Stage 2: Updating the New Long-Term Memory
This is where new info is injected. Two sub-parts happen:
- Candidate memory ()
- Computed from current input + previous short-term memory ().
- Tanh squashes it into range .
- Represents new knowledge I could add.
- Input gate ()
- Decides how much of this candidate memory should enter.
- Works like a filter:
- If , ignore new info.
- If , accept fully.
- Combine
- Old memory (partially kept) + New candidate info (partially added).
- This gives the updated long-term memory.
Interpretation: “Erase some old stuff, add some new stuff, keep the rest.”
Stage 3: Producing the Short-Term Memory (Hidden State)
Now we decide what to output for this step:
-
Output gate ()
- Looks at + .
- Decides which parts of memory to reveal.
-
Short-term memory
- Apply tanh to long-term memory (compress range).
- Multiply by output gate (select relevant parts).
Interpretation: “What part of my internal memory should I make visible right now as my working memory?”
Imagine you’re a student carrying a notebook through a lecture series:
-
Stage 1 (Forget gate): Before a new class, you erase some irrelevant notes.
-
Stage 2 (Input gate + candidate memory): You write down new things the teacher says, but only if they seem important.
-
Stage 3 (Output gate): When asked a question, you don’t read out your entire notebook you selectively share the part that matters.
GRU
BiLSTM
A Bidirectional Long Short-Term Memory (BiLSTM) is a type of recurrent neural network (RNN) architecture that is used to process sequential data. It extends the standard Long Short-Term Memory (LSTM) model by introducing the concept of bidirectionality, allowing the model to have both forward and backward information about the sequence.
The architecture of a BiLSTM is as follows:
- Input Layer: Takes the input sequence.
- Embedding Layer: Converts the input tokens to dense vectors (embeddings).
- Forward LSTM Layer: Processes the input sequence from start to end.
- Backward LSTM Layer: Processes the input sequence from end to start.
- Concatenation Layer: Combines the outputs from both the forward and backward LSTM layers.
- Dense Layer: Optional layer(s) for further processing.
- Output Layer: Produces the final predictions.
Resources
-
https://www.kaggle.com/code/fareselmenshawii/rnn-from-scratch
-
https://research.google/blog/a-neural-network-for-machine-translation-at-production-scale/
-
https://www.iamtk.co/building-a-recurrent-neural-network-from-scratch-with-python-and-mathematics
-
https://blog.otoro.net/2017/01/01/recurrent-neural-network-artist/
TO check
-
VISUALIZING AND UNDERSTANDING RECURRENT NETWORKS
-
Multilingual Machine Translation with Large Language Models: https://arxiv.org/pdf/2304.04675
-
On the difficulty of training Recurrent Neural Networks
-
https://dennybritz.com/posts/wildml/recurrent-neural-networks-tutorial-part-2/