
Over the past few months I’ve been building a fully open-source voice agent, exploring the stack end-to-end and learning a ton along the way. Now I’m ready to share everything I discovered.
The best part? In 2025 you actually can build one yourself. With today’s open-source models and frameworks you can piece together a real-time voice agent that listens, reasons, and talks back almost like a human without relying on closed platforms.
Let’s walk through the building blocks, step by step.
The Core Pipeline
At a high level, a modern voice agent looks like this:
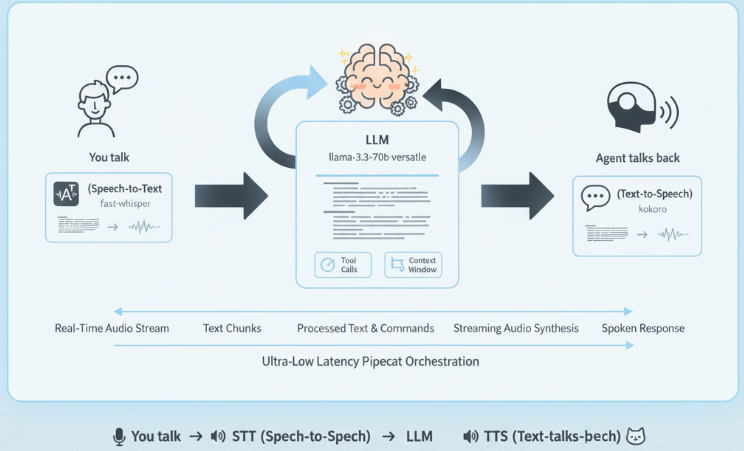
Pretty simple on paper but each step has its own challenges. Let’s dig deeper.
Speech-to-Text (STT)
Speech is a continuous audio wave it doesn’t naturally have clear sentence boundaries or pauses. That’s where Voice Activity Detection (VAD) comes in:
- VAD (Voice Activity Detection): Detects when the user starts and stops talking. Without it, your bot either cuts you off too soon or stares at you blankly.
Once the boundaries are clear, the audio is passed into an STT model for transcription.
Popular VAD
Silero VAD is the gold standard and pipecat has builtin support so I have choosen that :
- Sub-1ms per chunk on CPU
- Just 2MB in size
- Handles 6000+ languages
- Works with 8kHz & 16kHz audio
- MIT license (unrestricted use)
Popular STT Options
What are thing we need focus on choosing STT for voice agent
- Accuracy:
- Word Error Rate (WER): Measures transcription mistakes (lower is better).
- Example: WER 5% means 5 mistakes per 100 words.
- Sentence-level correctness: Some models may get individual words right but fail on sentence structure.
- Word Error Rate (WER): Measures transcription mistakes (lower is better).
- Multilingual support: If your users speak multiple languages, check language coverage.
- Noise tolerance: Can it handle background noise, music, or multiple speakers?
- Accent/voice variation handling: Works across accents, genders, and speech speeds.
- Voice Activity Detection (VAD) integration: Detects when speech starts and ends.
- Streaming: Most STT models work in batch mode (great for YouTube captions, bad for live conversations). For real-time agents, we need streaming output words should appear while you’re still speaking.
- Low Latency: Even 300 500ms delays feel unnatural. Target sub-second responses.
Whisper often comes first to mind for most people when discussing speech-to-text because it has a large community, numerous variants, and is backed by OpenAI.
OpenAI Whisper Family
- Whisper Large V3 — State-of-the-art accuracy with multilingual support
- Faster-Whisper — Optimized implementation using CTranslate2
- Distil-Whisper — Lightweight for resource-constrained environments
- WhisperX — Enhanced timestamps and speaker diarization
NVIDIA also offers some interesting STT models, though I haven’t tried them yet since Whisper works well for my use case. I’m just listing them here for you to explore:
- Canary Qwen 2.5B — Leading performance, 5.63% WER
- Parakeet TDT 0.6B V2 — Ultra-fast inference (3,386 RTFx)
Here the comparsion table
Why I Chose FastWhisper
After testing, my pick is FastWhisper, an optimized inference engine for Whisper.
Key Advantages:
- 12.5× faster than original Whisper
- 3× faster than Faster-Whisper with batching
- Sub-200ms latency possible with proper tuning
- Same accuracy as Whisper
- Runs on CPU & GPU with automatic fallback
It’s built in C++ + CTranslate2, supports batching, and integrates neatly with VAD.
For more you can check Speech to Text AI Model & Provider Leaderboard
Large Language Model (LLM)
Once speech is transcribed, the text goes into an LLM the “brain” of your agent.
What we want in an LLM for voice agents:
- Understands prompts, history, and context
- Generates responses quickly
- Supports tool calls (search, RAG, memory, APIs)
Leading Open-Source LLMs
Meta Llama Family
- Llama 3.3 70B — Open-source leader
- Llama 3.2 (1B, 3B, 11B) — Scaled for different deployments
- 128K context window — remembers long conversations
- Tool calling support — built-in function execution
Others
- Mistral 7B / Mixtral 8x7B — Efficient and competitive
- Qwen 2.5 — Strong multilingual support
- Google Gemma — Lightweight but solid
My Choice: Llama 3.3 70B Versatile
Why?
- Large context window → keeps conversations coherent
- Tool use built-in
- Widely supported in the open-source community
Text-to-Speech (TTS)
Now the agent needs to speak back and this is where quality can make or break the experience.
A poor TTS voice instantly ruins immersion. The key requirements are:
- Low latency avoid awkward pauses
- Natural speech no robotic tone
- Streaming output start speaking mid-sentence
Open-Source TTS Models I’ve Tried
There are plenty of open-source TTS models available. Here’s a snapshot of the ones I experimented with:
- Kokoro-82M — Lightweight, #1 on HuggingFace TTS Arena, blazing fast
- Chatterbox — Built on Llama, fast inference, rising adoption
- XTTS-v2 — Zero-shot voice cloning, 17 languages, streaming support
- FishSpeech — Natural dialogue flow
- Orpheus — Scales from 150M–3B
- Dia — A TTS model capable of generating ultra-realistic dialogue in one pass.
Why I Chose Kokoro-82M
Key Advantages:
- 5–15× smaller than competing models while maintaining high quality
- Runs under 300MB — edge-device friendly
- Sub-300ms latency
- High-fidelity 24kHz audio
- Streaming-first design — natural conversation flow
Limitations:
- No zero-shot voice cloning (uses a fixed voice library)
- Less expressive than XTTS-v2
- Relatively new model with a smaller community
You can also check out my minimal Kokoro-FastAPI server to experiment with it:
Speech-to-Speech Models
Speech-to-Speech (S2S) models represent an exciting advancement in AI, combining speech recognition, language understanding, and text-to-speech synthesis into a single, end-to-end pipeline. These models allow natural, real-time conversations by converting speech input directly into speech output, reducing latency and minimizing intermediate processing steps.
Some notable models in this space include:
-
Moshi: Developed by Kyutai-Labs, Moshi is a state-of-the-art speech-text foundation model designed for real-time full-duplex dialogue. Unlike traditional voice agents that process ASR, LLM, and TTS separately, Moshi handles the entire flow end-to-end.
-
CSM (Conversational Speech Model) is a speech generation model from Sesame that generates RVQ audio codes from text and audio inputs. The model architecture employs a Llama backbone and a smaller audio decoder that produces Mimi audio codes.
-
VALL-E & VALL-E X (Microsoft): These models support zero-shot voice conversion and speech-to-speech synthesis from limited voice samples.
-
AudioLM (Google Research): Leverages language modeling on audio tokens to generate high-quality speech continuation and synthesis.
Among these, I’ve primarily worked with Moshi. I’ve implemented it on a FastAPI server with streaming support, which allows you to test and interact with it in real-time. You can explore the FastAPI implementation here: FastAPI + Moshi GitHub.
Framework (The Glue)
Finally, you need something to tie all the pieces together: streaming audio, message passing, and orchestration.
Open-Source Frameworks
- Purpose-built for voice-first agents
- Streaming-first (ultra-low latency)
- Modular design — swap models easily
- Active community
- Developer-friendly, good docs
- Direct telephony integration
- Smaller community, less active
- Based on WebRTC
- Supports voice, video, text
- Self-hosting options
Traditional Orchestration
- LangChain — great for docs, weak at streaming
- LlamaIndex — RAG-focused, not optimized for voice
- Custom builds — total control, but high overhead
Why I Recommend Pipecat
Voice-Centric Features
- Streaming-first, frame-based pipeline (TTS can start before text is done)
- Smart Turn Detection v2 (intonation-aware)
- Built-in interruption handling
Production Ready
- Sub-500ms latency achievable
- Efficient for long-running agents
- Excellent docs + examples
- Strong, growing community
Real-World Performance
- ~500ms voice-to-voice latency in production
- Works with Twilio + phone systems
- Supports multi-agent orchestration
- Scales to thousands of concurrent users
| Feature | Pipecat | Vocode | LiveKit | LangChain |
|---|---|---|---|---|
| Voice-First Design | ✅ | ✅ | ⚠️ | ❌ |
| Real-Time Streaming | ✅ | ✅ | ✅ | ❌ |
| Vendor Neutral | ✅ | ✅ | ✅ | ⚠️ |
| Turn Detection | ✅ Smart V2 | ⚠️ Basic | ✅ | ❌ |
| Community Activity | ✅ High | ⚠️ Moderate | ✅ High | ✅ High |
| Learning Curve | ⚠️ Moderate | ⚠️ Moderate | ❌ Steep | ✅ Easy |
Lead to Next Part
In this first part, we’ve covered the core tech stack and models needed to build a real-time voice agent.
In the next part of the series, we’ll dive into integration with Pipecat, explore our voice architecture, and walk through deployment strategies. Later, we’ll show how to enhance your agent with RAG (Retrieval-Augmented Generation), memory features, and other advanced capabilities to make your voice assistant truly intelligent.
Stay tuned the next guide will turn all these building blocks into a working, real time voice agent you can actually deploy.
I’ve created a GitHub repository VoiceAgentGuide for this series, where we can store our notes and related resources. Don’t forget to check it out and share your feedback. Feel free to contribute or add missing content by submitting a pull request (PR).