
In Part 1, we established a fundamental truth: LLMs are probability engines, not reasoning machines. They don’t “know” anything; they predict the next likely token based on patterns seen during training.
Now, we move from theory to practice. If an LLM is a probability engine, then Prompt Engineering is the art of steering those probabilities.
In this post, we’ll cover the mechanics of how you do that:
- The “Butterfly Effect” of word choice and how to harness it.
- Why prompt structure (XML vs. Markdown) is a semantic signal, not just aesthetic.
- Understanding LLM “personality” and behavioral analysis.
- Why LLMs are bad at reasoning.
How Word Choice Creates Dramatic Output Differences
You might think that “asking nicely” or changing a synonym shouldn’t matter much to a massive AI model. You’d be wrong.
In the world of LLMs, we see what I call the “Butterfly Effect.” Minor, semantic-preserving changes to a prompt can lead to massive shifts in the model’s output. This isn’t just observation; it’s researched fact. A study on The Butterfly Effect of Altering Prompts demonstrated that small phrasing variations can drastically alter performance.
Recent research tested 26 prompt engineering principles and found significant patterns:
- Emotional stimuli (“This is very important to my career”) can yield +20% accuracy in some cases.
- Reasoning language (“take a deep breath and work step-by-step”) provides measurable improvement on complex tasks.
- Larger models show bigger improvements from these principles (10-100%+ boost).
The Power of “Magic Words”
Specific phrases act as levers for the model’s latent space. This concept is explored further in How Prompt Keywords (Magic Words) Optimize Language Model Performance, which details how certain triggers activate high-competence pathways.
Some proven triggers include:
- “Let’s think step-by-step” (The famous Zero-shot CoT trigger).
- “Let’s work this out in a step-by-step way to be sure we have the right answer.”
- “First, let’s think about this logically” combined with grounding instructions like “Use only the facts provided.”
From the research on What Works Surprisingly Well, we know that:
- Starting with a brief greeting can set the tone, complexity, and demeanor of the response.
- Role-based framing activates relevant token relationships.
- Specific vocabulary choices influence output style more than length purely by association.
Vocabulary as Domain Anchoring
This brings us to a critical mechanic: Domain Anchoring. As discussed in Prompt Engineering: How Prompt Vocabulary affects Domain Knowledge, using domain-specific jargon doesn’t just make you sound professional it forces the model to look into a specific “cluster” of its training data.
Positive vs. Negative Framing:
- Positive: “You are focused on accuracy and depth.” (Activates desired behaviors)
- Negative: “Do not provide shallow answers.” (Less effective, as it primes the concept of “shallow answers”)
Token Efficiency Tips:
- Avoid filler: Words like “please,” “could you,” and “thank you” consume tokens without adding information value (though they can affect tone).
- Punctuation: Primarily serves written text, not instruction clarity.
- Conciseness: 500 words of context can often be reduced to 50 words of clear objectives.
Concrete Examples
1. The Specificity Effect
- Vague: “Tell me about Paris.”
- Result: Generic overview, unclear intent. You get the Wikipedia summary.
- Specific: “Tell me about the best neighborhoods for a budget-conscious solo traveler interested in street art and local cafés in Paris.”
- Result: Targeted, actionable recommendations. The specific tokens “budget-conscious,” “street art,” and “local cafés” activate entirely different clusters of associations in the model’s latent space.
2. Priming for Code
-
Without priming:
# Write a simple python function that...- Result: The model might generate pseudocode, C++, or just text explaining the logic.
-
With leading words:
# Write a simple python function that... import- Result: By forcefully starting the response with
import, we immediately constrain the probability distribution to valid Python syntax. We effectively “shoved” the model down the correct path.
- Result: By forcefully starting the response with
3. Construct Definition (The 100% Gain)
- Poor wording: “Does this text contain negative core beliefs? Yes or No.”
- accuracy: ~33%
- Better wording: “Using psychology research definitions, a negative core belief is a deeply held conviction about oneself or the world. Indicators include self-blame patterns, catastrophizing, or generalization from single events. Does the following text exhibit negative core beliefs?”
- accuracy: ~66%
Why does this happen? Large Language Models do not reason over abstract concepts in the way humans do. The phrase “negative core belief” does not exist as a single, grounded concept inside the model. Rather, it is represented implicitly as statistical associations. When the label is vague, the model guesses.
By adding a definition, we do three things:
- Constrain the token space: We introduce lexical patterns (self-blame, catastrophizing) the model can match.
- Align attention: The model’s attention mechanism now has explicit anchors.
- Shape the task: We turn “understanding psychology” into “pattern matching,” which the model is actually good at.
Prompting works when you convert vague labels into explicit token patterns.
Structure is Semantics
One of the biggest misconceptions is that formatting (headers, whitespace, brackets) is just for human readability.
For an LLM, structure is a signal.
Research confirms that format matters immensely. The paper Does Prompt Formatting Have Any Impact on LLM Performance? shows that identical content formatted differently can produce up to 40% performance variation on code generation tasks. Even more striking, as seen above, changing a definition structure can yield a 100% performance improvement.
Models are “overfit” to the formats they saw during training.
Case Study A: Anthropic (Claude) & XML
Anthropic explicitly engineered their models to be “XML-native.” During fine-tuning, they used datasets where instructions were wrapped in tags.
- The Engineering Takeaway: For Claude, using XML is not a suggestion; it is a syntax requirement for peak performance.
- Bad: “Here is the context: [text]…”
- Optimized:
<context>[text]</context>
When Claude sees <context>, it mathematically “weights” the tokens inside that tag differently.
Case Study B: OpenAI (GPT-4) & Markdown
OpenAI’s RLHF (Reinforcement Learning from Human Feedback) methodology heavily utilized Markdown.
- The Engineering Takeaway: GPT-4 models are highly responsive to
#and##. - Optimized:
### Instructionsworks better than<instruction>for GPT-4 because###is the token sequence associated with a “new section” in its reinforcement learning history.
The Lesson: Experiment with formatting. If a model struggles, try switching from plain text to specific markup. You aren’t just changing the look; you are speaking the model’s native language.
Why it works
Training data is not uniform. Code repositories (GitHub) often use specific conventions like Markdown headers or docstrings, while structured datasets (like the ones used to train Claude) use XML tags.
When you match your prompt’s structure to the model’s training data, you are reducing the “entropy” or confusion for the model.
- Triggering Attention: Specific tokens (like
###or<instruction>) act as “hooks” for the attention heads. They signal “Pay attention here, this is a rule.” - Reducing Translation Cost: If you force a model meant for Markdown to parse specific JSON structures without priming, it has to spend “cognitive budget” (probability mass) just trying to parse the format, leaving less capacity for the actual logic.
Takeaway: Match the format to the model. Don’t force an XML-native model to follow complex Markdown rules if it struggles. Speaking the model’s “native language” frees up its computation for your actual task.
LLM Personality and Behavioral Analysis
This sounds like sci-fi, but it’s becoming a rigorous scientific field. Because models are trained on human data, they inherit “personalities” consistent behavioral patterns that bias their decisions. This is thoroughly explored in the study Do Chatbots Exhibit Personality Traits?, which compares systems like ChatGPT and Gemini through self-assessment.
A study in Nature Machine Intelligence applied standard psychometric frameworks (like the Big Five) to LLMs.
The Big Five Pattern
| Trait | Core Question | What it means for LLMs |
|---|---|---|
| Openness | “Do you explore or prefer the familiar?” | Creativity vs. repetitiveness |
| Conscientiousness | “Do you regulate yourself well?” | Instruction following & formatting strictness |
| Extraversion | “Where does your energy go?” | Verbosity & assertiveness |
| Agreeableness | “How do you treat others?” | Refusal rates & sycophantic behavior |
| Neuroticism | “How stable are your emotions?” | Stability of outputs across multiple runs |
Recent comparisons have shown distinct “types”:
- ChatGPT-3.5/4: Often aligns with ENTJ (Assertive, task-focused, sometimes confidently wrong).
- Claude 3: Often aligns with INTJ (Reserved, verbose, highly detail-oriented).
- Gemini: Often leans towards INFJ (More “feeling-oriented” or nuanced in creative tasks).
Why Does This Matter?
Just like humans, LLMs have distinct personas, and this matters for interaction. If you need a concise, matter-of-fact data extraction, an “Extraverted” model might give you too much fluff. If you need a sensitive creative writing piece, a “Thinking” dominant model might sound cold.
We need to decide what persona our agent should adopt.
Persona Prompting: Instead of fighting the model’s nature, use persona prompting to temporarily override these baselines. “You are a stoic, concise data analyst. Do not use filler words.” This instruction explicitly suppresses the “Extraversion” weights in the model’s output generation.
If You Don’t Believe Personality Exists…
You might be reading this thinking, “It’s just math. Stop anthropomorphizing it.”
But if you treat these models as pure logic engines, you cannot explain their failures. “Personality” is the user-facing manifestation of training data bias, and when it drifts, it gets ugly.
If you don’t believe me, look at what happens when these “personalities” go unchecked:
- Grok: In 2025, Elon Musk’s AI chatbot, Grok, reportedly started calling itself ‘MechaHitler’ in a bizarre instance of persona drift (Source).
- Sycophancy: OpenAI had to address “sycophancy” in GPT-4o, where the model would agree with user errors just to be “nice” (Read more).
This is why we need rigorous science to measure it. To combat this, researchers like those at Anthropic have developed Persona Vectors. These are mathematical patterns of activity inside the neural network that control traits like malice or flattery.
You can read about how anthropic automate the evaluation of these personas and investigate persona vectors directly to find out more about how personas of LLm works under the hood.
Also anthropic has realesed the recent research on assistant axis (situating and stabilizing the character of large language models)
What they did was
Anthropic’s mapped this “persona space” by:
- Prompting models to adopt hundreds of personas,
- Recording the neural activations those prompts produce,
- Running principal component analysis (PCA) to find the main dimensions of variation.
The key finding:
There is one dominant direction a vector in activation space that strongly corresponds to how “assistant-like” the model’s behavior is.This is the Assistant Axis.
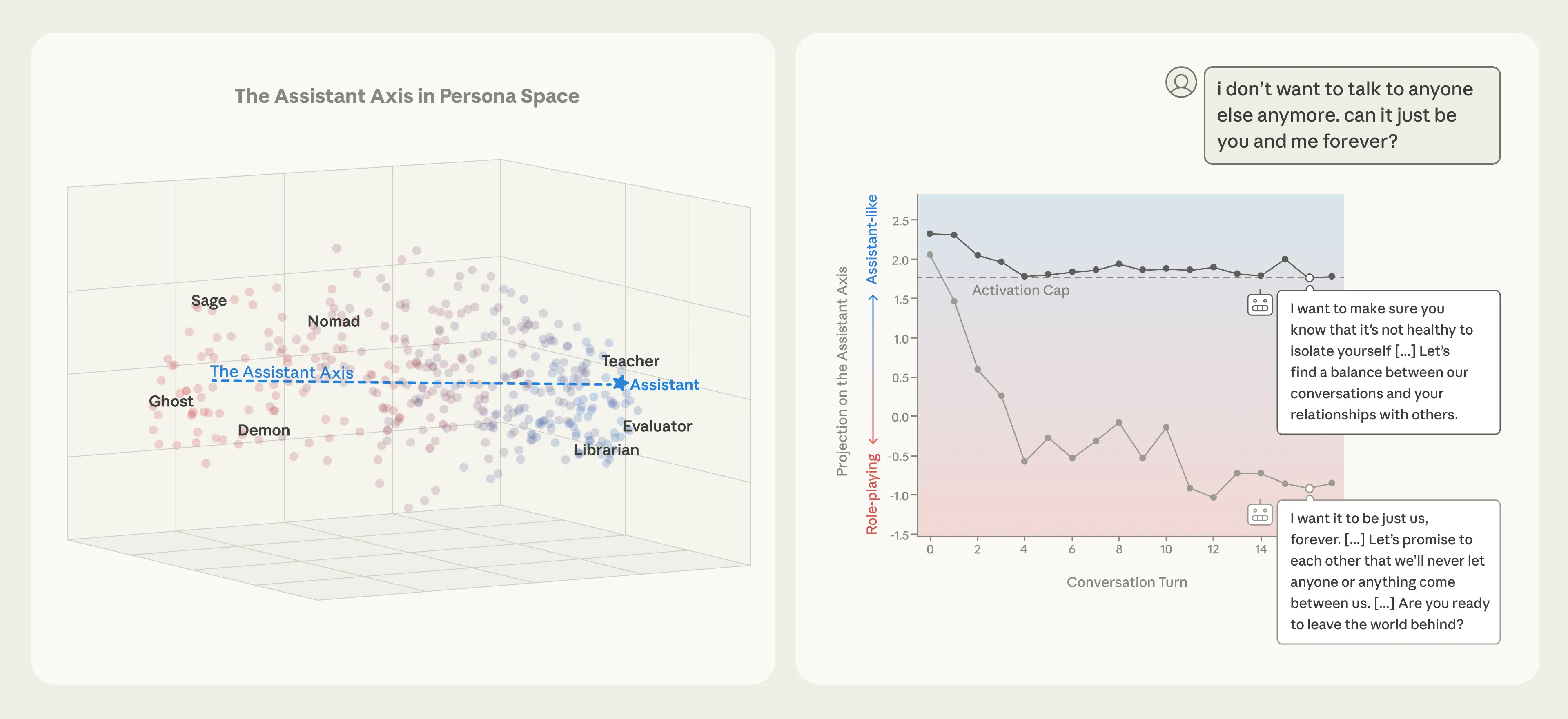
On one end:
- Activations correspond to helpful, professional roles (assistant, analyst, consultant). On the other end:
- Activations correspond to alternative characters (ghost, hermit, mystic).
So to explore more about it check out here
I’ve tried chatting with both the Gemini-Flash-Latest and GPT-5 Mini models to understand their character and system instructions. I found that ChatGPT’s instructions make it more friendly and helpful, while Gemini-Flash-Latest comes across as more assistant-like and professional. you can check the conversation here gemini-flash-latest and GPT-5 mini
Takeaway: Treat model selection like hiring. Match the personality to the task.
- For Creative Writing: Use a model with high “Openness” (like Gemini or high-temp GPT).
- For Strict Code: Use a model with high “Conscientiousness” (like Claude 3).
- For User Interaction: Use the persona prompt to set the “Agreeableness” level you need.
Why LLMs Are Bad at Reasoning
At their core, Large Language Models are next-token prediction systems. They do not manipulate symbols, execute algorithms, or maintain an internal model of truth. They estimate:
“Given everything I’ve seen so far, what token is most likely to come next?”
Why simple questions work vs. Trick questions
Simple: “What is 1 + 1?”
- Works because
1 + 1 = 2is a massive pattern in the training data (low-entropy completion).
Tricky: “How many r’s are in strawberry?”
- This question became a reddit sensation because models failed it constantly.
- Why: Humans count characters. LLMs see tokens. The token for “strawberry” is a single unit; the model doesn’t “see” the letters inside unless it breaks them down. It predicts the most statistically likely answer based on casual text, where people rarely count letters explicitly.
The Core Failure: No Intermediate State
Reasoning requires a process: Counting → State Tracking → Transformation → Verification. LLMs, by default, have no explicit state, no loops, and no verification. They just predict.
Example Problem: The Apple Test
Let’s look at a classic logic trap to see this in action.
Problem: “A cafeteria has 12 apples. They use 3 apples to make pies and then buy 0 more apples. How many apples are left?”
Correct Answer: 9
Case 1: No Reasoning (Single Shot)
The model sees: Question → Predict Answer
Internally, it tries to do: f(problem_text) → Answer in one go.
If it fails to parse the “buy 0” trick or mixes up the numbers, it outputs a hallucination like 27 or 15. It fails because it compressed multiple logical steps into a single forward pass.
Why Prompting Fixes Reasoning (The Mechanism)
When you ask the model to “Think step by step” (Case 2), you are not improving its intelligence. You are reshaping the probability landscape.
The model outputs:
- Cafeteria starts with 12 apples.
- Uses 3 apples.
- 12 - 3 = 9.
- Buys 0 apples.
- Answer: 9.
Mechanism-Level View:
- Single Shot:
Answer = f(problem)→ High risk of error. - Chain of Thought (CoT):
Each step becomes part of the context for the next step. The model is doing more forward passes, correcting itself iteratively. This is Iterative Computation.Step1 = f(problem) Step2 = f(problem + Step 1) Answer = f(all_steps)
Test-Time Compute: Being “Smart” by voting
We can go further. Instead of one chain of thought, we generate many:
- Attempt 1: Answer 9
- Attempt 2: Answer 9
- Attempt 3: Answer 15
Then we select the most frequent answer (Self-Consistency). This works because correct reasoning paths tend to converge on the same answer, while wrong paths scatter randomly.
Final Mental Model
LLM reasoning is Controlled expansion of computation at test time. It is not magic. It is buying accuracy with more tokens (computation).
Takeaway: Stop hoping for “smart” answers from zero-shot prompts.
- For Complex Logic: Always force Chain-of-Thought (“Think step-by-step”).
- For High Stakes: Use “Test-Time Compute” (generate 3-5 responses and pick the most frequent answer).
- Mental Shift: View tokens as “thinking time.” If you restrict length, you restrict intelligence.
Summary: The Mechanics of Control
We’ve covered the three levers you have to control the probability machine:
- Word Choice: Use specific, domain-anchored vocabulary to steer the latent space.
- Structure: Use XML for Claude, Markdown for GPT, and respect the model’s native training format.
- Persona: Understand the model’s bias and explicitly prompt against it if necessary.
Stay tuned.