
Are you overpaying for AI because of your language? If you’re building LLM applications in Spanish, Hindi, or Greek, you could be spending up to 6 times more than English users for the exact same functionality.
This blog insipred from the research paper Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models
The Hidden Tokenization Tax
When you send text to GPT-4, Claude, or Gemini, your input gets broken into tokens chunks roughly 3-4 characters long in English. You pay per token for both input and output.
The shocking truth: The same sentence costs wildly different amounts depending on your language.
Real Example: “Hello, my name is Sarah”
| Language | Tokens Needed | Cost vs English | Annual Cost (10K msgs/day) |
|---|---|---|---|
| English | 7 tokens | 1.0x baseline | $16,425 |
| Spanish | 11 tokens | 1.5x more | $24,638 (+$8,213) |
| Hindi | 35 tokens | 5.0x more | $82,125 (+$65,700) |
| Greek | 42 tokens | 6.0x more | $98,550 (+$82,125) |
That’s an $82,000 annual difference for the exact same chatbot purely because of language.
The Complete Language Cost Breakdown
Research from ACL 2023 and recent LLM benchmarks reveals systematic bias in how models tokenize different languages. Here’s what it costs to process 24 major languages:
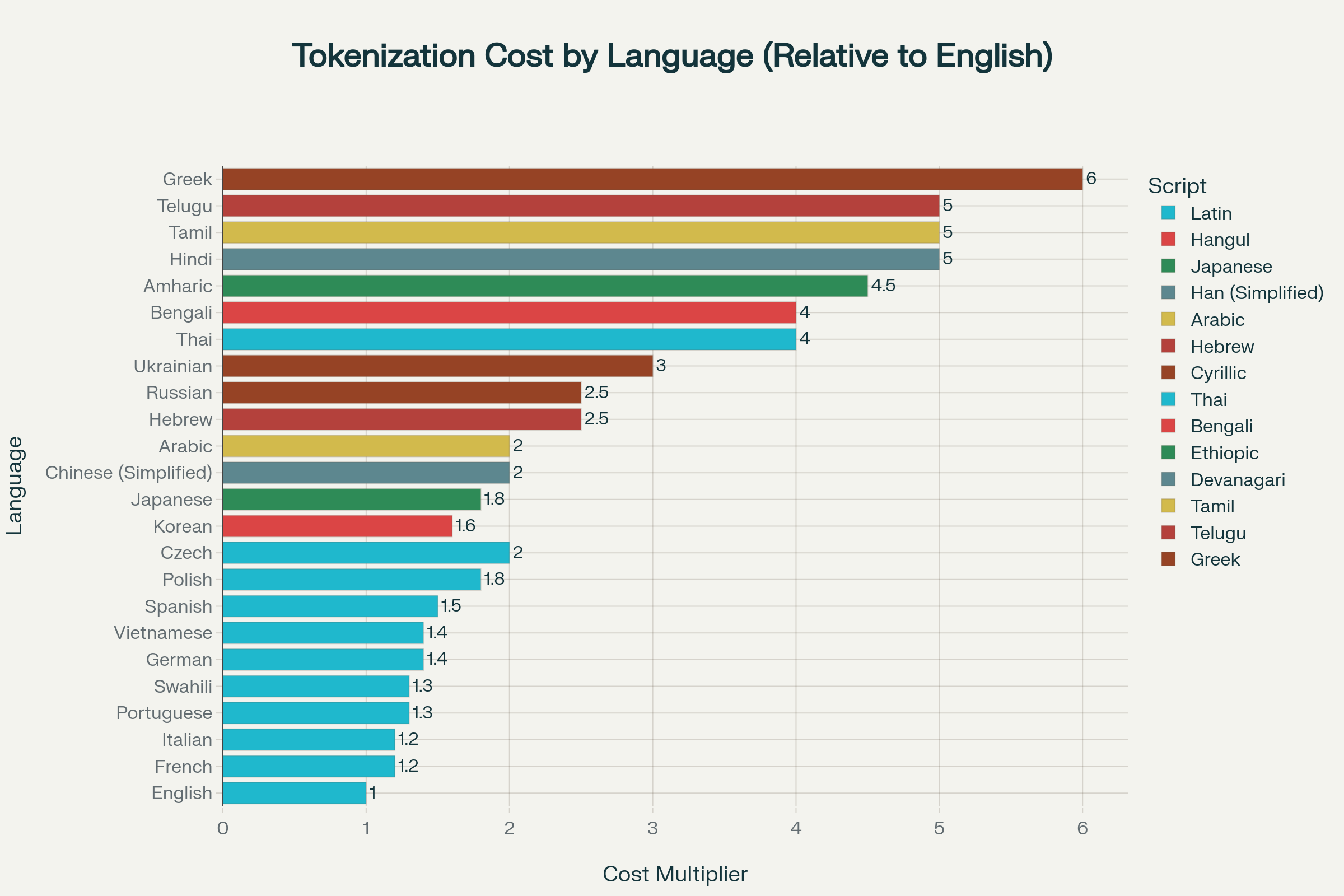
Tokenization cost comparison across 24 languages showing how many times more expensive each language is compared to English due to tokenization differences
Most Efficient Languages (1.0-1.5x English)
- English: 1.0x (baseline)
- French: 1.2x
- Italian: 1.2x
- Portuguese: 1.3x
- Spanish: 1.5x
Moderately Expensive (1.6-2.5x)
- Korean: 1.6x
- Japanese: 1.8x
- Chinese (Simplified): 2.0x
- Arabic: 2.0x
- Russian: 2.5x
Highly Expensive (3.0-6.0x)
- Ukrainian: 3.0x
- Bengali: 4.0x
- Thai: 4.0x
- Hindi: 5.0x
- Tamil: 5.0x
- Telugu: 5.0x
- Greek: 6.0x (most expensive)
Why Writing Systems Matter
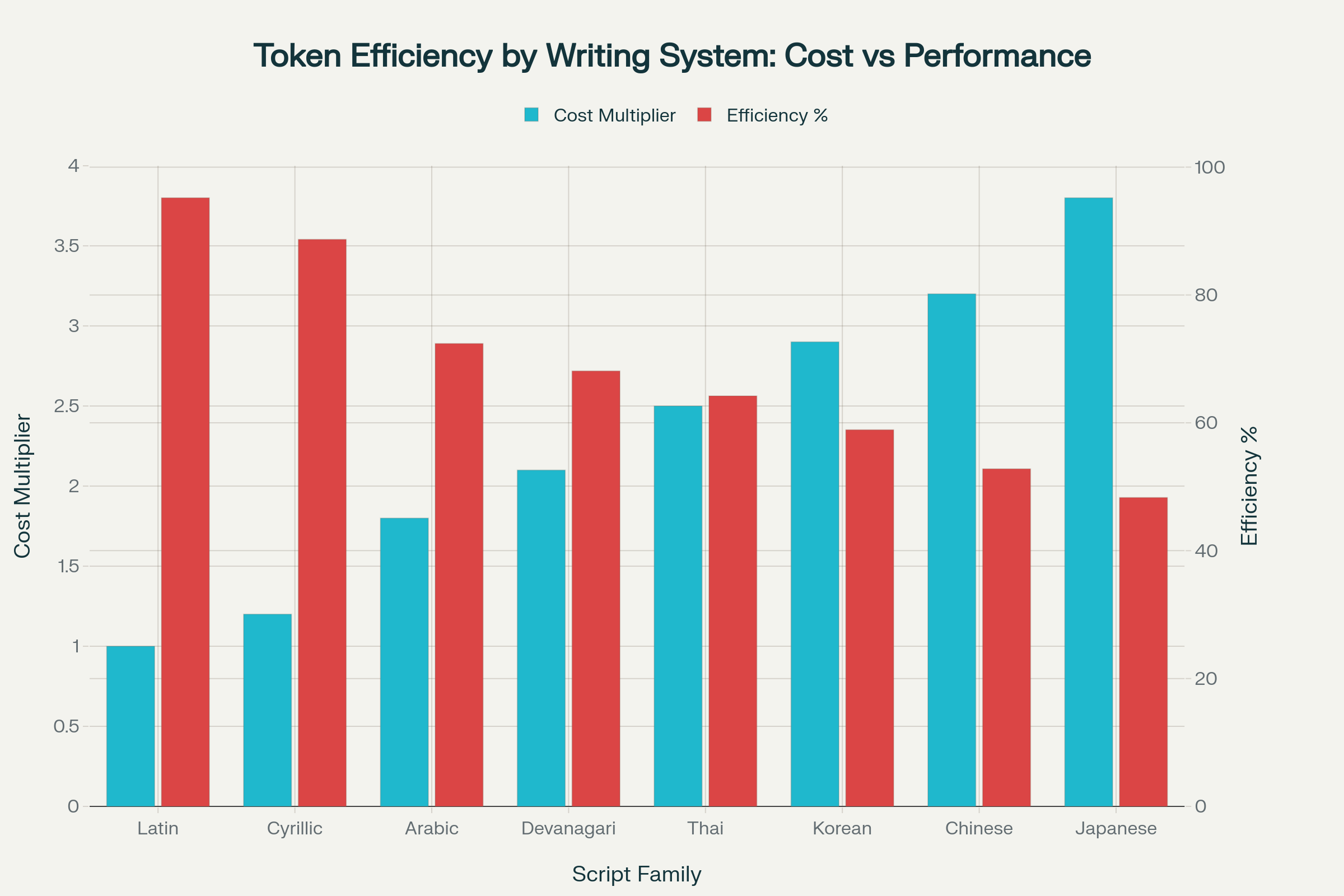
Comparison of tokenization costs and efficiency across different writing systems, showing why Latin-based languages are most cost-effective for LLM applications
The script your language uses creates dramatic efficiency gaps:
- Latin script: 1.4x average (73.5% efficient)
- Hangul (Korean): 1.6x (63% efficient)
- Han/Japanese: 1.8-2.0x (50-56% efficient)
- Cyrillic: 2.75x average (36.5% efficient)
- Indic scripts: 4-5x average (20% efficient)
- Greek: 6.0x (17% efficient—worst)
Why This Inequality Exists
1. Training Data Bias
GPT-4, Claude, and Gemini are trained on English-dominant datasets. The Common Crawl corpus shows stark imbalance:
- ~60% English
- ~10-15% combined for Spanish/French/German
- <5% for most other languages
Tokenizers learn to compress what they see most. English gets ultra-efficient encoding; everything else is treated as “foreign.”
2. Morphological Complexity
Languages with rich morphology generate far more word variations
- English: “run” → runs, running, ran (4 forms)
- Turkish: Single root → 50+ forms with suffixes
- Arabic: Root system → thousands of variations
- Hindi: Complex verb conjugations with gender/number/tense
Tokenizers can’t learn compact patterns for high-variation, low-data languages.
3. Unicode Encoding Overhead
Different scripts need different byte counts:
- Latin: 1 byte per character
- Cyrillic: 2 bytes per character
- Devanagari/Tamil: 3+ bytes per character
More bytes = more tokens = higher cost—even for the same semantic content.
Real-World Cost Impact
Here’s what tokenization inequality means for actual business applications:
Customer Support Chatbot (10,000 messages/day)
- English: $16,425/year
- Spanish: $24,638/year (+50%, +$8,213)
- Hindi: $82,125/year (+400%, +$65,700)
Content Generation Platform (1M words/month)
- English: $14,400/year
- Spanish: $21,600/year
- Hindi: $72,000/year
Document Translation Service (100K words/day)
- English: $65,700/year
- Spanish: $98,550/year (+$32,850)
- Hindi: $328,500/year (+$262,800)
Code Assistant (50K queries/day)
- English: $91,250/year
- Spanish: $136,875/year
- Hindi: $456,250/year (+$365,000)
Bottom line: A company serving Hindi users pays $262,800-$365,000 more annually than an identical English service.
The Socioeconomic Dimension
Research reveals a disturbing -0.5 correlation between a country’s Human Development Index and LLM tokenization cost.
Translation: Less developed countries often speak languages that cost more to process.
- Users in developing nations pay premium rates
- Communities with fewer resources face higher AI barriers
- This creates “double unfairness” in AI democratization
Example: A startup in India building a Hindi customer service bot pays 5x more than a US competitor despite likely having far less funding.
The Future of Fair AI
Language should never determine how much intelligence costs. Yet today, the world’s most spoken tongues pay a silent premium just to access the same models. Fixing this isn’t about optimization it’s about fairness. Until every language is tokenized equally, AI remains fluent in inequality.